周晶雨,王士同
江南大学 人工智能与计算机学院,江苏 无锡214122
在机器学习领域中,迁移学习作为一项重要的技术,多年来进行了广泛的研究[1-2]。许多应用中的模型是根据大量训练数据构建的,然而收集和标记足够的数据是困难且昂贵的[3-4]。迁移学习的主要目的是利用从一个或多个源域中提取的有用信息来提高目标域的学习性能。一个典型的例子是,收集足够的老虎数据是困难的,但猫的数据是丰富的,迁移学习可以用来建立一个利用猫数据的老虎分类模型。因此迁移学习显著的好处就是,利用源域中的有用知识提高整体函数预测性能,并减少昂贵的数据标记工作。因此,迁移学习已经被应用到各个领域,赵鹏飞等人[5]阐述了不同的迁移学习方法在人机对话系统的意识识别任务中的应用。任豪等人[6]介绍了迁移学习在跨领域的推荐算法上的应用。
迁移学习研究之初仅从一个源域迁移知识到目标域[1,7-8],但在某些实际应用的情况中,可以轻松地从多个源域中将学习到的知识迁移到目标域[9]。以五种语言文档分类应用为例,为了对英文编写的文档进行分类,可以利用从法语翻译成英语的文档、德语翻译成英语的文档、西班牙语和意大利语翻译成英语的文档中学习知识,每个翻译文档都可以被作为源域[10]。然而,不同的源域对于目标域的贡献也是不相同的,为了克服此限制,可以采用基于Boosting[9,11]的方法来设计更复杂的多源迁移学习算法。
大多数多源迁移学习是在离线环境下进行的[12-14]。在某些实际应用中,目标域的训练数据并不是事先提供的,而是在目标域函数学习的过程中以顺序的方式接受的,称为在线迁移学习[1-2,15]。在大数据时代,在线学习能够处理传统批处理算法无法胜任的大量的且快速增长的数据任务。在线学习中,目标域函数每轮接受一个样本及其对应标签,然后使用目标函数对当前样本进行预测,得到预测结果。然后根据当前样本的真实标签和预测结果之间的损失信息更新目标函数。孙勇等人[16]将在线学习应用到大规模服务计算中,改善了预测的时间效率,同时也满足了计算的实时性要求。对于多源在线迁移学习,每轮到达样本的最终预测结果通过组合多个源分类器和目标分类器的预测结果得到。
目前,大多数的迁移学习算法都没有关注不平衡的数据集,而是默认数据的类别分布是平衡的,但是不平衡数据往往存在于许多现实世界的分类问题中。对于不平衡的数据集,传统的分类器对不同类别假设相同的误分类代价,虽然可以给出较高的分类精度,但算法的性能会受到不平衡数据的严重影响,因为将一个少数类样本错分为多数类样本的代价是极其昂贵的。以前的文章提出了多种方法来处理类别不平衡的数据集,大致可以分为以数据为基础的采样方法、成本敏感方法和算法级的方法[17]。以数据驱动的采样方法在训练分类器之前对数据集进行预处理,通过分布均衡的数据来解决不平衡的问题。成本敏感的方法对错误分类少数类样本的决策函数施加更高的惩罚。而算法级的方法则是修改像支持向量机[18-19]这样的分类器来解决类别不平衡的问题。
多源在线迁移学习中,目标域从多个源域提取有用的知识来帮助目标函数分类。Wu 等人[20]提出了一种可以利用多个与目标域相关的源域来进行在线迁移学习的算法。Kang 等人[21]提出一种多源在线迁移学习的多类分类算法,通过两阶段集成策略进行多类分类。周晶雨等人[22]提出一种多源在线迁移学习方法,在线训练的过程中对目标域的少数类样本进行扩增,从而提高整体分类性能。然而在现实环中,大多数分类任务中的数据通常是类别分布不平衡的。不平衡数据分类是机器学习领域的一个重要的研究课题,它在多源在线迁移学习中也很重要。在多源在线迁移学习中,源域和目标域的数据类别都有可能是不平衡的。当目标域数据不平衡时,目标域函数的预测结果偏向于多数类;
当源域数据不平衡时,组合多个源分类器和目标分类器的结果极有可能偏向于多数类;
当源域和目标域的数据都不平衡时,会产生更加复杂的情况。显然,针对不平衡数据集的多源在线迁移学习是一个重要而富有挑战性的课题,值得广泛研究。
本文提出了一种称为OTLMS_STO(multi-source online migration learning based on oversampling in source and target domain feature space)的多源在线迁移学习算法,该算法主要研究不平衡数据的二分类问题。现有的方法将源域和目标域函数通过权重向量在在线学习的过程中动态地组合起来,但是并未考虑源域数据和目标域数据类别分布同时不平衡的情况,而本文提出的OTLMS_STO 算法分别在源域和目标域的特征空间中对少数类样本进行过采样,使用平衡的数据训练源函数,并在在线预测的过程中改进目标函数,有效解决了类别分布不平衡的问题。在对源域过采样阶段,每个源域都使用SVM 作为分类器,在源域的特征空间中合成少数类样本,通过平衡数据生成的Gram 矩阵来训练各个源域的SVM 分类器。对在线的目标域过采样阶段,采用被动攻击算法(passive-aggressive,PA)[23]构建目标域的决策函数。目标域每轮到达一批数据,从前面已经达到批次的少数类样本中寻找k近邻。然后在种子和邻居样本对之间的线段上合成少数类新样本,使用生成的新样本和当前批次中原始样本去训练目标域的决策函数。最后通过权重向量组合改进后的源和目标函数。源和目标域中生成的样本具有线性可分的性质,可以克服SMOTE(synthetic minority oversampling technique)[24]方法在过采样过程中对于非线性问题的局限性。并且在多个文本和图像数据集上进行了实验,结果表明提出的算法与在线迁移学习的基线算法相比具有更好的性能。
在本章中,主要介绍多源在线迁移学习算法HomOTLMS[20]。HomOTLMS 将在多个源域和目标域上构建的分类器结合在一起,实现有效的集成分类器。通过利用多个源域的有用信息,解决目标域样本数据不足的问题,最终提升目标域的性能。
HomOTLMS 首先根据预先给出的m个源域的训练数据,在离线批处理学习范式中构建它们的决策函数。而对于目标域,采用在线被动攻击算法构建一个以在线的方式更新的决策函数gT(x)。目标域每轮接受一个样本,在第i轮,目标域接受到实例(xi,yi),然后使用函数对给定的实例xi进行预测,并根据真实标签yi计算目标域决策函数的铰链损失:
如果决策函数在实例xj上遭受非零损失,那么就将其作为支持向量添加到支持向量集中来更新目标域的决策函数:
其中,τi=min{C,Li/k(xi,xi)},k(·,·)是核函数。
HomOTLMS 通过每轮目标域的样本来训练目标域决策函数,并同时调整各分类器权重来更新最终的集成决策函数,从而进行有效的多源在线迁移学习。但是HomOTLMS 算法并不能有效地应对源域或者目标域数据类别分布不均匀的情况。下面介绍了一种新的多源在线迁移学习方法,可以通过人工平衡源域和目标域类别的分布,降低总体分类误差。
2.1 问题描述
本节正式介绍多源在线迁移学习中数据类别分布不均的问题。对于给定的m个源域,使用DS=来表示,目标域使用DT表示。使用表示第j个源域的数据空间,其中该源域的特征空间是。对于目标域,其数据空间使用X×Y 表示,其中特征空间是X=Rd。并且这里的源域和目标域共享相同的标签空间=Y={+1,-1},也同时共享相同的特征空间,即对∀j=1,2,…,m,=Rd。
与HomOTLMS 不同的是,提出的算法主要应用于目标域每次以在线的方式到达一批数据的问题。对于目标域,第t个批次的数据是。当一个批次的样本到达时,目标域的决策函数依次预测每个样本并更新自身,而m个源域则直接预测本批次的样本,得到m组预测结果。最后遍历m个源域和目标域的预测结果来调整集成决策函数的各项权重,并得到当前批次的最终预测结果。
源域采用SVM 训练分类器,目标域采用在线被动攻击算法(PA)训练分类器,源域和目标域都是在特征空间通过训练得到一个最佳的分离超平面来预测样本。当类别不平衡时,这个超平面可能会对多数类样本更加敏感,预测结果偏向多数类。对于源域和目标域的数据,它们的类别分布都可能是不均匀的,假设类别为+1 的样本是少数类,类别为-1 的样本是多数类。使用不平衡的源域数据训练出来多个源分类器,这时目标域从源域迁移的知识可能会偏向多数类,会对目标域的数据造成负面的影响。如果目标域数据本身就是不平衡的,那么有极大的可能会使目标决策函数向多数类偏斜,从而影响最终的集成决策函数的结果。当源域和目标域的数据都不平衡时,往往会产生更加复杂的情况。本文提出的OTLMS_STO 算法通过在源域和目标域的样本特征空间中进行过采样,提高集成决策函数的整体分类性能,更好地实现知识迁移。
2.2 在源域的特征空间中过采样
提出的OTLMS_STO 算法首先在源域的特征空间中过采样,利用采样后平衡的数据集改进源域的分类器。在多个源域中使用SVM 这样的基本分类器,SVM 在高维隐式特征空间中识别分离超平面来对样本进行分类。对于不平衡的数据集,SMOTE[24]是一种优秀的采样方法,利用领域的信息来综合生成少数类样本点,它在两个相邻的样本之间的线段上生成新样本。但是对于高维的文本和图像数据,SMOTE 局限于这样的非线性可分的问题。
由于多个源域的SVM 分类器是在特征空间中运行的,可以在同一个特征空间中生成合成样本来处理类不平衡的问题。图1 展示了提出的OTLMS_STO算法在改进多个源域阶段时的结构,主要分为两个关键步骤:第一步,在源域的特征空间中生成合成的少数类新样本,使得源域的数据集变平衡;
第二步,使用修改后的平衡数据集训练得到多个源域的分类器。下面详细描述各个步骤。

图1 OTLMS_STO 算法在处理源域阶段的结构Fig.1 Structure of OTLMS_STO algorithm in process of source domain
其中,k(·,·)是核函数,通过核函数计算种子和邻居之间的距离而不需要知道φ(x)函数的具体形式。
当求得了源域中所有少数类样本的k近邻后,会得到许多组种子和邻居对,从中选择适量组数的样本对并在它们之间的线段上生成一个新的样本。生成的新的少数类样本的数量Lt_new要使当前源域的类别分布相对平均,并且为每个新样本分配一个标签。根据下面公式在特征空间中合成新样本:
其中,αmn是一个0 到1 之间的随机数,在公式使用的过程随机生成,参照文献[25]中的设置。
注意,当目标域中+1 标签的样本是少数类时,并不能肯定在每个源域中+1 标签的也是少数类,因此在平衡源域数据时需要根据两种类别具体的样本数确定少数类。
通过Gram 矩阵K1可以训练源域的SVM 分类器,K1是由源域中每对样本的内积组成的:
将生成的Lt_new个新样本添加到Gram 矩阵K1中训练源域的SVM 分类器,新的Gram 矩阵表示为:
根据式(9)和式(10)可知,增广核矩阵K仅由源域中的训练样本和核函数k(·,·)构成,而不需要知道映射函数φ(x)的具体形式。因此,任何一个有效的核函数都可以用来训练源域的SVM,而提出的OTLMS_STO 算法使用高斯核函数来训练SVM。
2.3 在目标域的特征空间中过采样
本节主要介绍提出的OTLMS_STO 算法对不平衡目标域的处理步骤。目标域使用PA 算法进行训练,PA 算法也出现类似于SVM 的优化问题,预测机制基于一个超平面,该超平面将实例空间分成两个半空间。在对目标域函数改进的阶段中,目标决策函数能够利用与SVM 分类器相同的核技巧,合成样本利用特征空间中的点积生成而不需要知道特征映射函数φ(x)。因此可以通过相同的核函数和带宽来控制源域和目标域生成的新样本处于相同的特征空间。目标域生成的数据点在高维的空间具有更好的线性可分性,可以用来改进目标决策函数。
图2 展示了提出的OTLMS_STO 算法在改进目标域阶段的结构,目标域的样本分成多个批次到达,目标域到达一批数据时的处理过程分为三步:第一步,对当前批次中的少数类样本过采样,使类别分布相对均衡。图2中是原始样本,表示合成的新样本。第二步,遍历生成的新样本,依次训练目标决策函数gT(x)。第三步,使用当前批次中的原始样本进行多源在线迁移学习。对所有的批次采用相同的三个步骤处理就可得到最后训练好的集成函数,下面详细描述各个步骤。
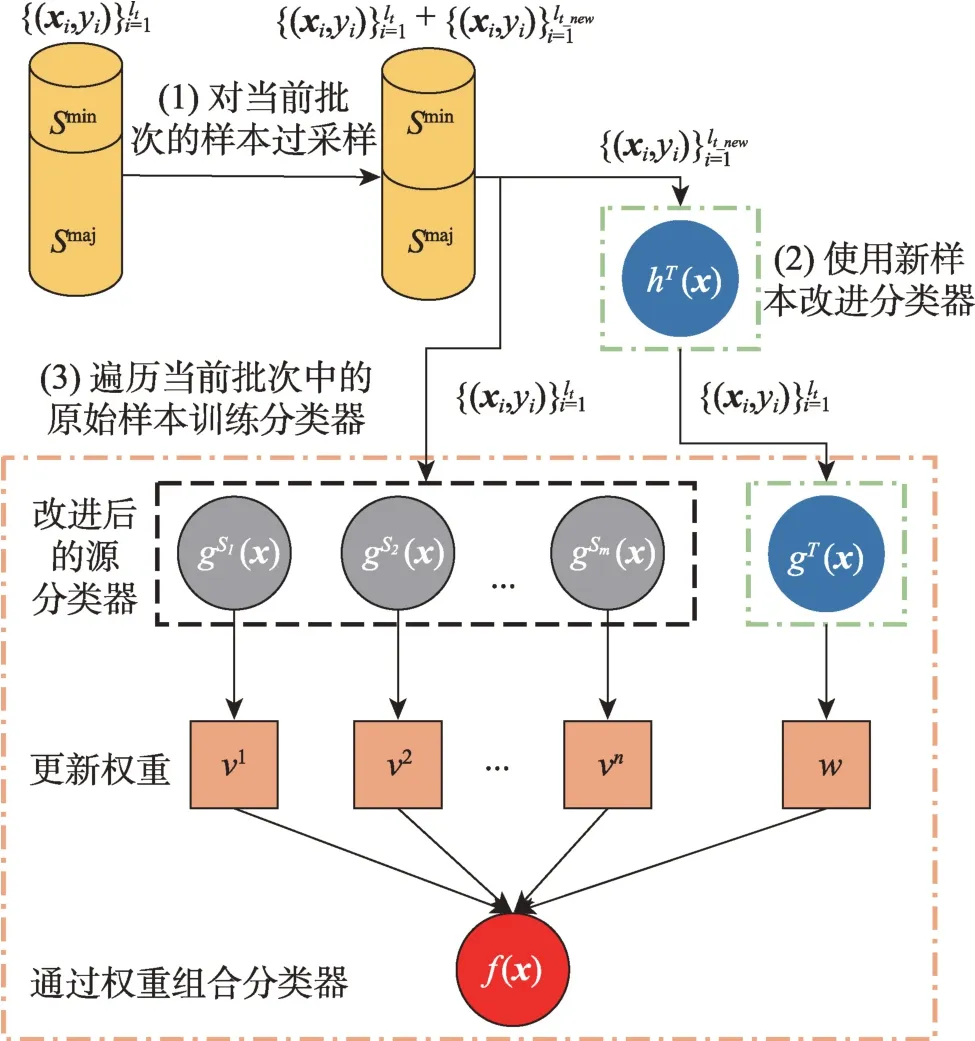
图2 OTLMS_STO 算法在处理目标域阶段的结构Fig.2 Structure of OTLMS_STO algorithm in process of target domain
在目标域第t个批次的样本到达时,OTLMS_STO 算法会从中挑选出所有的少数类样本。然后从前面已经到达的多个批次中寻找当前到达批次中每个少数类样本的k近邻。对于当前批次中少数类种子φ(xm) 和前面批次中的少数类邻居φ(xn),使用式(5)计算两者在特征空间的距离。并且用表示种子和邻居组成的样本对的集合,一共对,同时给每对样本分配+1 的标签。然后从集合中随机选取min_num个少数类的样本对,根据式(6)在特征空间中合成新的样本。其中,min_num的大小要使当前批次中的少数类和多数类样本的数量近似,即数据类别平衡。
在对当前批次的样本进行多源在线迁移学习之前,先用生成的新样本改进目标决策函数gT(x)。然而,根据式(6)生成的新少数类样本利用通常未知的特征映射函数φ(x),因此新的合成样本φ(xmn)并不能具体得到。目标决策函数采用PA 算法,每次通过核函数计算两个样本的内积来添加支持向量,从而改进目标函数。因此当目标函数接收到在特征空间生成的新样本时,可以根据式(9)计算普通样本和合成样本的内积,根据式(10)计算合成样本和合成样本的内积,从而利用新样本训练目标决策函数。与改进源域阶段类似,只需知道训练样本和核函数k(·,·),而不需要知道映射函数φ(x)的具体形式。
使用合成实例改进目标域决策函数,当铰链损失大于0 时,将合成实例作为支持向量添加到支持向量集,并且也能保持特征空间的可分性,即:
定理1在目标域的特征空间中生成合成的少数类样本同样能保证类别可分。
证明目标域函数由支持向量组成,可以表示为:
将式(6)生成少数类样本φ(xpq))代入目标函数:
其中,gT(xm),gT(xn)≥0,xm,xn都属于少数类,αmn∈[0,1]。
因此在目标域的特征空间中生成的样本同样可以保证类别可分。每批次生成的新样本都会优化目标函数在特征空间中的超平面,提高目标函数的性能。然后对当前批次中的所有样本进行多源在线迁移学习,得到本批次的最终结果。
2.4 算法描述与复杂度分析
提出的OTLMS_STO 算法总共分为两个阶段:(1)改进多个源域的分类器;
(2)改进目标域的分类器,使用改进的源分类器进行多源在线迁移学习。
第一阶段的算法描述和复杂度分析:
上述算法中,步骤2.1 寻找所有的少数类样本的时间复杂度为O(N),N是当前源域的样本总数。步骤2.2 寻找所有少数类样本的k近邻的时间复杂度是O(n_min2),n_num是当前源域中少数类样本的个数。步骤2.4 中计算Gram 矩阵的时间复杂度是O((N+n_num)2d),其中d是样本的维度。因此总的时间复杂度是O(n(N+n_min2+(N+n_num)2d)),n是源域的个数,可以近似为O(nd(N+n_num)2)。
第二阶段的算法描述和复杂度分析:
上述算法中,步骤1.1 寻找k近邻的时间复杂度是O(3m1m2d),其中m1和m2分别是当前批次和前面批次中的少数类和多数类,d是样本的维数。步骤1.3 利用合成样本改进目标决策函数的时间复杂度是O(4svd),s是新样本的总数,v是支持向量的个数。步骤1.4 训练当前批次原始样本的时间复杂度是O(2nvd),一共n个样本。整个目标域共有N个批次,总的时间复杂度是O(N(3m1m2d+4svd+2nvd)),可以近似为O(N(m1m2d+svd+nvd))。
本章将提出的OTLMS_STO 算法与多个在线学习的基线算法进行了比较,并在真实世界的数据集上进行了实验:20Newsgroups 数据集、Office-Home数据集、Modern Office-31 数据集和DomainNet 数据集。为了获得可靠的结果,在相同参数设置的前提下,将多个源域的数据作为训练数据,将目标域的数据作为测试数据,通过更改测试实例的到达顺序来将每个实验重复10 次。结果表明,提出的算法比基线算法获得了更好的性能。
3.1 数据集介绍
(1)20Newsgroups
20 个新闻组数据集(http://qwone.com/~jason/20Newsgroups/)是机器学习技术中进行文本应用的流行数据集,该数据集收集了大约20 000 个新闻组文档,平均分成20 个不同主题的新闻组。其中,每个新闻组都对应一个不同的主题,一些新闻组彼此之间有着非常紧密的联系,而其他新闻组则高度不相关。高度相关的构成5 个大的主题,如os、ibm、mac和x 是comp 主题的新闻组,crypt、electronics、med 和space 是sci 主题的新闻组。在实验中,将comp 主题中的新闻组标记为正例,sci 主题的新闻组标记为负例。从而可以构建4 个相关的学习域:os_vs_crypt、ibm_vs_electronics、mac_vs_med 和x_vs_space。从中随机选择1 个域作为目标域,其余3 个域作为源域,可以生成4 个迁移学习任务。每组任务的不平衡率都为0.3。
(2)Office-Home
Office-Home[26]数据集包含来自4 个不同邻域的图像艺术图像(Art)、剪贴画(Clipart)、产品图像(Product)和现实世界图像(Real World),共有15 500张左右的图像。其中每个域都包含65 个类别的图像。在实验设置中,将Real World 领域的图像作为目标域,Art、Clipart 和Product 这3 个域作为源域。在Real World 域的65 个类别中选择1 个样本数少的和1个样本数多的构成二分类任务的目标域,3 个源域也选取相同的类别,形成一个迁移学习的任务。在实验之前,对任务中的原始图片进行简单的预处理,将每张图片都处理成一个1×10 000 的向量。实验一共生成了33 组迁移学习任务。在33 组任务中,Real World 域有1 组任务不平衡率在[0.1,0.2)之间,不平衡率在[0.2,0.3)之间的有14 组任务,不平衡率在[0.3,0.4)之间的有18 组任务。
(3)DomainNet
DomainNet 数据集[13]是迄今为止最大的域适应数据集,该数据集由6 个不同的域、345 个类别和约60 万张图片组成。6 个域分别是Clipart、Infograph、Painting、Quickdraw、Real 和Sketch,而类别则是从家具、布料、电子到哺乳动物、建筑等。在实验中,从Real照片和真实世界图像域中选取1 个样本少的和1个样本多的类构成目标域,其余5 个域作为源域,构成一个迁移学习任务。实验中一共生成了45 组迁移学习任务。在45 组任务中,Real域有5 组任务不平衡率在[0,0.1)之间,不平衡率在[0.1,0.2)之间的有7组任务,不平衡率在[0.2,0.3)之间的有33 组任务。
自2012年全面启动新型职业农民培育工作以来,农业农村部制定了一系列支持新型职业农民培育和发展的文件,明确了新型职业农民的培育原则,细分了培育类型和标准。尤其在“十三五”中,把习总书记提出的“坚持把科教兴农、人才强农、新型职业农民固农”作为农业农村发展的重大战略,也为新型职业农民培育工作指出了方向。
(4)Modern Office-31
Modern Office-31 数据集[27]是一个用于图像分类的迁移学习数据集。其包含4 个领域的子集:Amazon(A)、Webcam(W)、Synthetic、Dslr(D),分为31 个类别,共有7 210 张图片。在Modern Office-31 数据集中,不仅各个领域的样本总数不同,而且各个域内部类别分布也不平衡,可以通过不平衡方法处理Modern Office-31 数据集,促使迁移学习效果提升。实验中,预处理数据集,每个图片都是1×10 000 的向量。将Webcam 作为目标域,其余3 个域作为源域。然后选取Webcam 中的一个样本数多的和一个样本数少的类别构成一组迁移学习任务,一共生成了20 组任务。在20组任务中,Webcam域有5组任务不平衡率在[0.2,0.3)之间,不平衡率在[0.3,0.4)之间的有9 组任务,不平衡率在[0.4,0.5)之间的有6 组任务。
3.2 基线算法和评价指标
为了评估提出的OTLMS_STO 算法的性能,将该算法与最新的几种在线学习方法进行了对比实验。PA 算法[23]是一种经典的在线学习算法,使用PA作为对比算法并不需要进行知识迁移。使用各个源域的数据先对PA 进行初始化来实现PA 算法的一种变体“PAIO”。同时还与一种著名的多源在线迁移学习算法HomOTLMS[20]进行了对比,该算法可以利用多个源域的有用知识来提高目标域的分类性能。另外将提出的算法与OTLMS_IO[22]以及OTLMS_FO[22]进行了比较,两种算法都是通过对不平衡的目标域过采样提升性能,前者在输入空间采样,后者在特征空间采样。所有算法均由Python 语言实现。
对不平衡数据集上的分类器进行性能评价,如果使用准确率或者错误率这样单一的评价标准通常是无效的。本文实验采用准确度和G-mean 来评估数据集的性能,G-mean 可以评价不平衡数据的模型表现。当样本都被划分到同一个类时,G-mean 的值是0,表1 是二分类混淆矩阵,G-mean 的计算公式是:
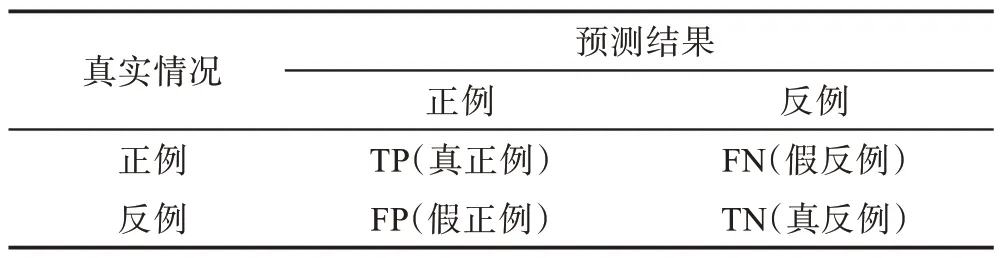
表1 二分类混淆矩阵Table 1 Two-classification confusion matrix
3.3 参数设置和实验结果
3.3.1 参数设置
在20Newsgroups、Office-Home、DomainNet和Modern Office-31 数据集上,将提出的OTLMS_STO 算法与4 种迁移学习的基线算法进行了对比实验。为了使比较更加公平,所有算法都采用了尽可能相似的实验设置。对于每批次少数类样本的k近邻,OTLMS_STO 会自动设置k值,保证生成的少数类新样本能够使当前批次的类别分布相对均衡。由于高斯核函数的广泛应用,本文采用高斯核训练函数,本文提出的算法也可以使用其他的核函数,并且在[10-2,102]范围中搜索最优的带宽σ。在3.3.7 小节的实验中分析了不同折衷参数C值带来的实验性能的影响,并设置所有算法在全部数据集上的折衷参数C为5。根据文献[20]对算法错误界的分析,可以得到权重折扣参数β=,其中m是算法所犯的错误数,n是源分类器的个数。
3.3.2 20Newsgroups数据集上的实验结果
表2 列出了20Newsgroups 数据集上多种比较算法的性能,评价指标包括准确率和G-mean。从实验结果可以观察到,提出的OTLMS_STO 算法在4组学习任务中取得了比所有基线算法更好的性能。OTLMS_STO 算法的性能优于PA 和PAIO,这表明提出的算法能有效地从多个源域中提取知识。在4 组任务中,提出的OTLMS_STO 算法比HomOTLMS 的结果更好,这是因为HomOTLMS算法忽略了源域和目标域数据类别不平衡的问题。比较算法OTLMS_IO 和OTLMS_FO 的性能要优于HomOTLMS,但是两个比较算法都只考虑了在目标域中扩增样本,而提出的OTLMS_STO 算法在源域和目标域的特征空间中扩增少数类的样本。图3 给出了4 组任务中不同算法的错误率随着样本数增加而变化的折线图。从图3可以看出,随着训练样本数的增加,6种算法的错误率也显著降低。并且OTLMS_STO 算法在os_vs_crypt、mac_vs_med 和x_vs_space 的任务中始终比对比方法的错误率低。其中,HomOTLMS、OTLMS_IO、OTLMS_FO和OTLMS_STO 算法在开始样本数少的时候有着更好的结果,这证明上述算法都可以有效地从多个源域提取知识。本文提出的OTLMS_STO 算法的错误率在大多数任务上比其他算法更低,证明了提出的算法能有效改进不平衡源域和目标域。

图3 20Newsgroups数据集上各算法随样本数增加的错误率Fig.3 Error rate of each algorithm on 20Newsgroups dataset with increase of the number of samples

表2 在20Newsgroups数据集上应用不同学习算法的结果(平均±标准差)Table 2 Results of different learning algorithms on 20Newsgroups dataset(mean±standard deviations) 单位:%
在图像数据集Office-Home上进行了33组实验任务,表3 给出了所有对比算法在两种指标上的数值结果。其中,HomOTLMS、OTLMS_IO、OTLMS_FO和OTLMS_STO算法比普通的在线学习算法有着更好的性能,这表明从多个源域迁移知识有助于目标域的预测。而OTLMS_STO、OTLMS_IO 和OTLMS_FO 比HomOTLMS 的评价更好,因为前面三种算法都考虑到目标域类别不平衡的情况。
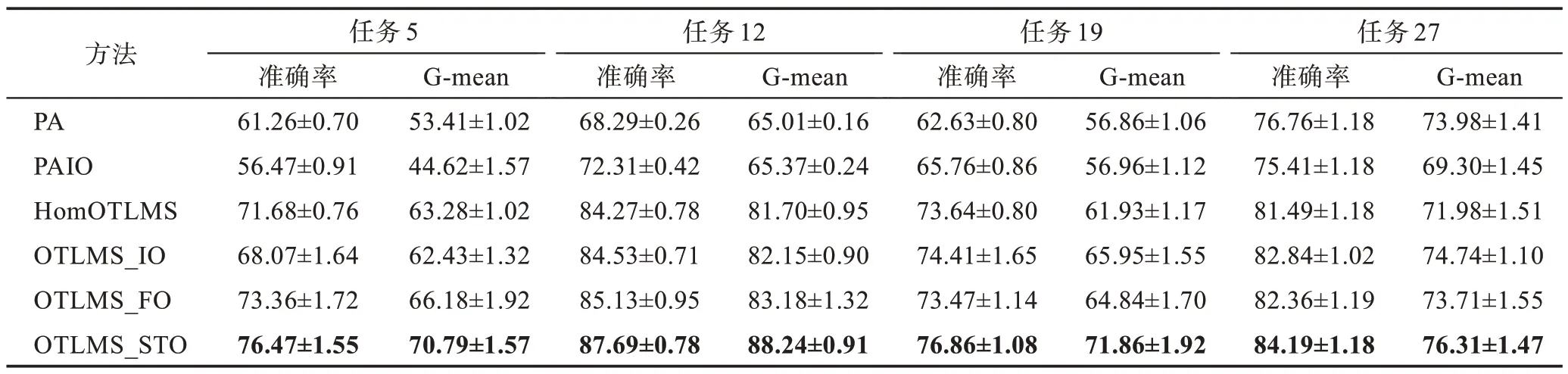
表3 在Office-Home数据集上应用不同学习算法的结果(平均±标准差)Table 3 Results of different learning algorithms on Office-Home dataset(mean±standard deviations) 单位:%
但是OTLMS_STO 算法的性能更优,该算法可以同时从源域和目标域的核空间中扩增少数类的样本,有效修正特征空间中的超平面,从G-mean 指标能够清晰看到分类器的变化。图4 展示三种主要算法在33 组任务上准确率的柱状图,图5 展示了33 组任务G-mean 指标的折线图。在绝大多数任务上,OTLMS_STO 算法的性能都要更优,并且对少数类有着更好的效果。这表明提出的算法不仅能从多个源域迁移知识,还能很好地应对不平衡的数据集。
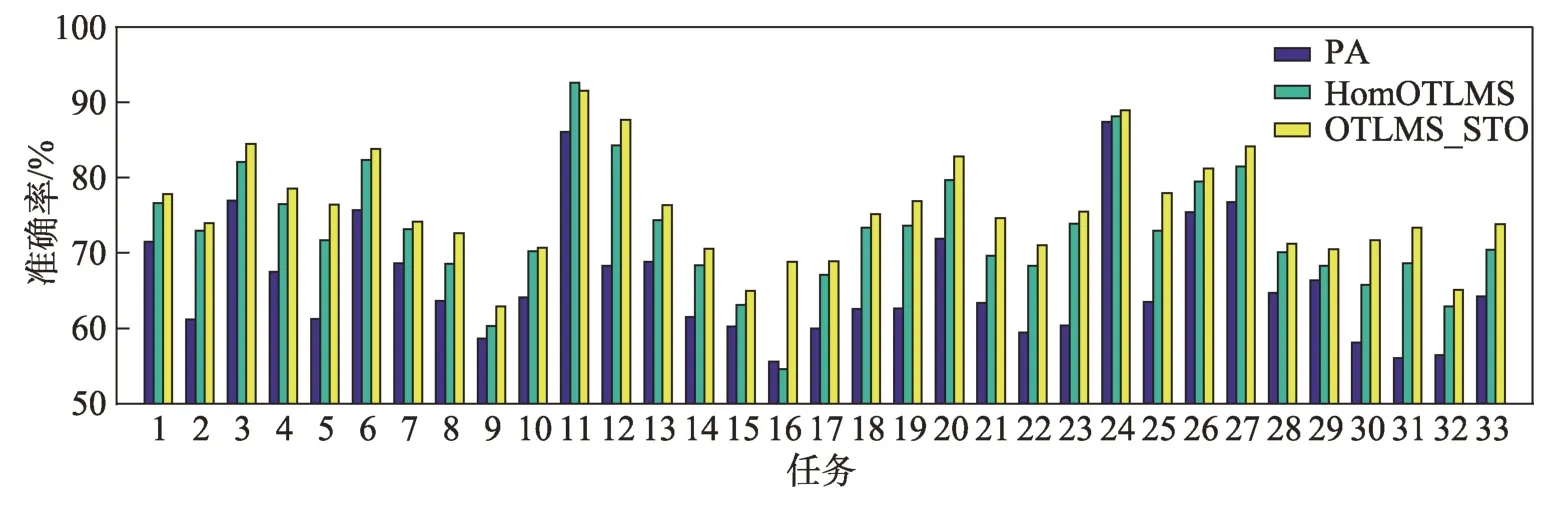
图4 Office-Home数据集的33 组任务的准确率Fig.4 Accuracy of 33 groups of tasks on Office-Home dataset
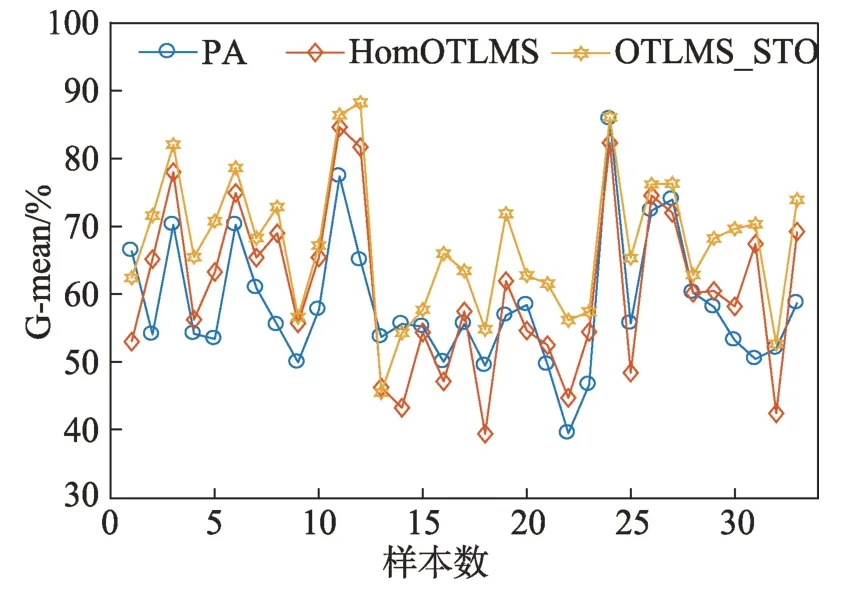
图5 Office-Home数据集上各组任务的G-meanFig.5 G-mean of each group of tasks on Office-Home
3.3.4 DomainNet数据集上的实验结果
为了更好地验证OTLMS_STO 算法的性能,在图像数据集DomainNet 上一共进行了60 组实验任务。表4 给出了4 组任务的数值结果,实验结果中的数据显然是支持提出的方法,并在所有任务中都获得了超越对比算法的最优性能。这表明提出的OTLMS_STO 算法能够从多个源域提取有效知识,并对于源域和目标域不平衡的情况也有很好的效果。DomainNet 数据集一共包含5 个源域,组合源域和目标域时,目标域所占的比重只有1/6,因此OTLMS_FO通过扩增目标域的样本改进目标决策函数的性能一般。而提出的OTLMS_STO 算法可以在源域的核空间中合成少数类样本,然后使用增广的核矩阵训练源域分类器,通过组合多个源分类器和目标分类器就能实现更好的性能。受空间性和可观测性的影响,图6 展示了PA、HomOTLMS 和OTLMS_STO 算法在45 组任务中的结果,而忽略了其他算法的结果。在大多数任务中,提出的算法都要优于两种比较算法。图7展示了3种主要算法的G-mean值,结果表明提出的OTLMS_STO 算法能够应对不平衡的数据,尤其对源域数量较多的数据集有着更好的性能。

图6 DomainNet数据集的45 组任务的准确率Fig.6 Accuracy of 45 groups of tasks on DomainNet dataset

图7 DomainNet数据集上各组任务的G-meanFig.7 G-mean of each group of tasks on DomainNet dataset
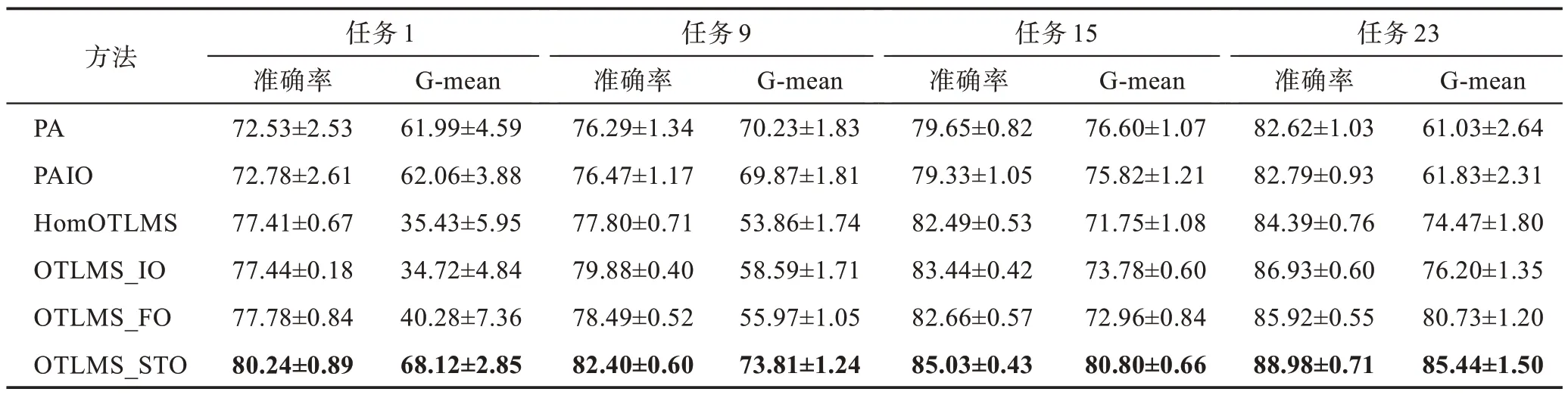
表4 在DomainNet数据集上应用不同学习算法的结果(平均±标准差)Table 4 Results of different learning algorithms on DomainNet dataset(mean±standard deviations) 单位:%
3.3.5 Modern Office-31 数据集上的实验结果
在Modern Office-31 图像数据集上一共进行了20 组实验任务。表5 给出了在几个随机选择的任务上使用所有算法的准确率和G-mean 的数值结果。本文提出的OTLMS_STO 算法通过利用多个源域的有用信息来增强目标域的分类性能,因此在准确率指标上,OTLMS_STO 实现了具有竞争力的性能。与此同时,OTLMS_STO 在源域和目标域的特征空间上对少数类样本进行扩增,同时改进源域和目标域的函数,避免最终的集成决策函数偏向于多数类别。从表5中观察到,OTLMS_STO算法在G-mean指标上达到了最优的性能。

表5 在Modern Office-31 数据集上应用不同学习算法的结果(平均±标准差)Table 5 Results of different learning algorithms on Modern Office-31 dataset(mean±standard deviations) 单位:%
图8 展示了Modern Office-31 数据集上20 组实验任务在PA、HomOTLMS和OTLMS_STO算法上的平均准确率结果。从图中可以看到提出的OTLMS_STO算法在绝大多数的任务上都有着最优的性能,这证明了提出的算法可以有效利用源域的知识来提高性能,并且证明了同时在源域和目标域的特征空间中扩增样本对函数性能的有效性。图9给出了20组实验任务在PA、HomOTLMS和OTLMS_STO算法上的G-mean结果,证明了OTLMS_STO应对不平衡数据的有效性。
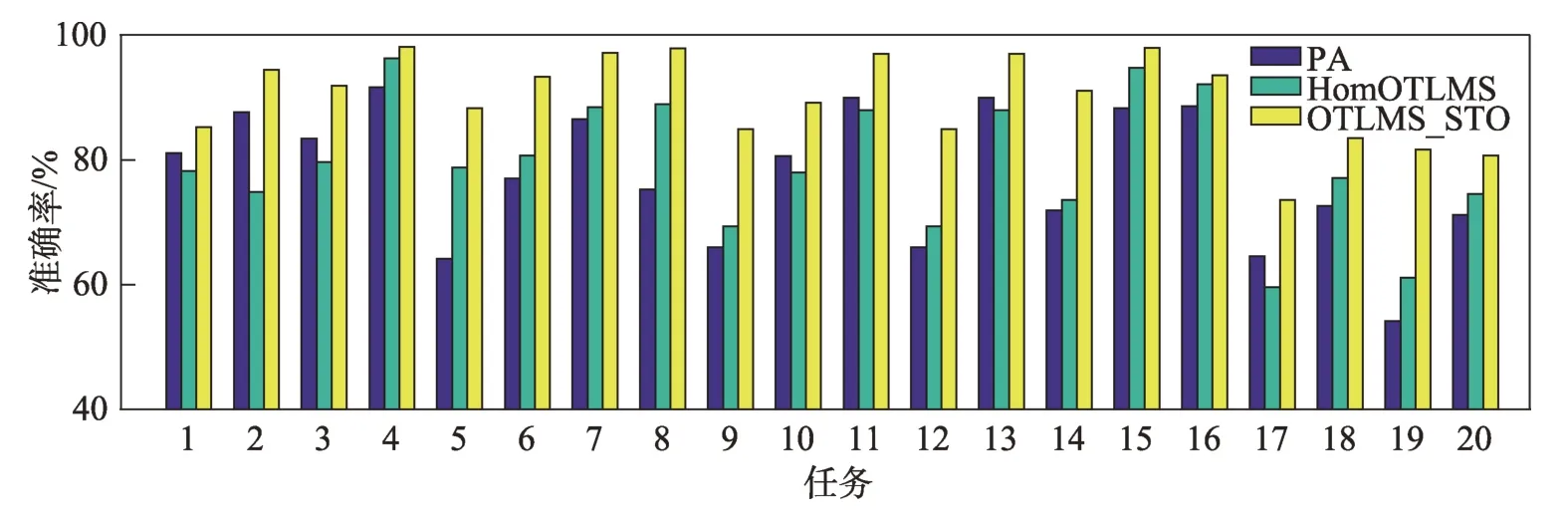
图8 Modern Office-31 数据集的20 组任务的准确率Fig.8 Accuracy of 20 groups of tasks on Modern Office-31 dataset

图9 Modern Office-31 数据集上各组任务的G-meanFig.9 G-mean of each group of tasks on Modern Office-31 dataset
3.3.6 在全部数据集上准确率的rank值
表6 给出了在3 种数据集上一共102 组实验任务准确率的rank 值结果以及每个数据集上的平均rank值。在5 种算法的准确率排名中,排名第一的rank 值为1,排名第二的rank 值为2,后面的以此类推。对于20Newsgroups 数据集,task1~4 表示任务1、任务2、任务3和任务4,后面的1 1 1 1是task1~4 的rank值结果。从表格中可以看出,在绝大多数的任务中,提出的OTLMS_STO 算法的实验结果排名都处于第一名的位置,并且平均rank 值也有很好的表现。
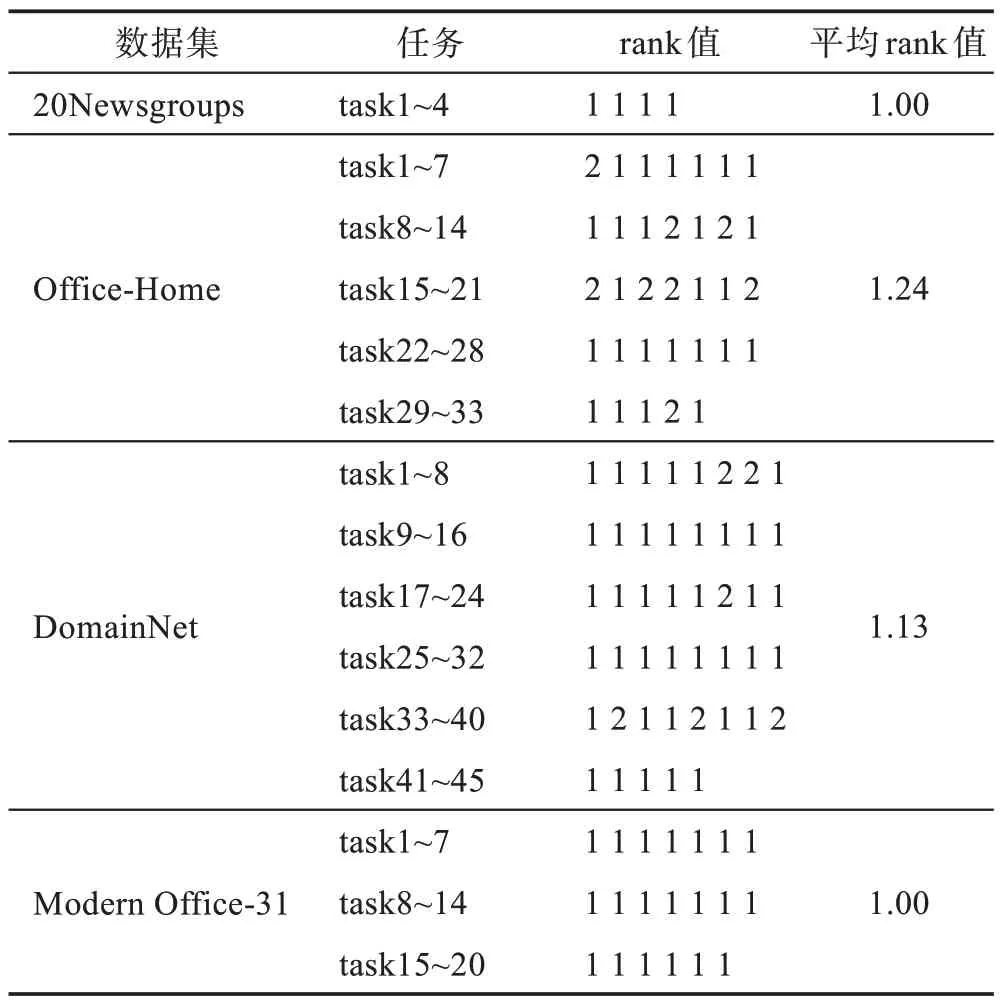
表6 每组任务准确率的rank 值以及平均rank值Table 6 Rank value and average rank value of task accuracy in each group
3.3.7 参数调整
本文提出的方法涉及一些可调参数,包括折衷参数C。图10展示了不同C值对20Newsgroups数据集的潜在影响。从图中可以观察到,OTLMS_STO 和其他方法的精度随着不同的C而显著变化。对于同一任务,不同的算法在不同的C值上获得最佳性能。从图10 中可以得出结论,在不同的C值下,OTLMS_STO 算法比其他迁移学习算法更准确且更加稳定,这验证了所提出算法的有效性。在实验中,将所有算法的C值设为5。

图10 20Newsgroups数据集上不同C 值的全部算法评价Fig.10 Evaluation of all algorithms with different C values on 20Newsgroups dataset
3.4 时间成本
为了评估提出算法随着训练样本增加的时间效率,本文在多个任务上测试了所有的算法。实验使用python 实现,运行在一台6×2.6 GHz CPU 处理器和16 GB 内存的Windows 机器上。本文算法的平均运行时间记录并总结在图11 中。从图中可以发现,随着样本数量的增加,本文算法的平均运行时间比其他算法花费得更多。然而,考虑到更好的性能,增加的时间成本是可以接受的。

图11 随着样本数增加的各个算法的时间成本Fig.11 Time cost of each algorithm with increase of the number of samples
本文考虑了不平衡数据的在线迁移学习问题,其中目标域的数据分批次到达,并从多个离线源域中迁移知识。针对不平衡的源域,本文算法在源域的特征空间中扩增少数类样本至源域类别平衡,然后使用增广的核矩阵训练源域,形成多个改进后的离线源域分类器。针对不平衡的目标域,该算法从前面到达批次中的少数类样本中寻找当前批次样本中少数类的k近邻,然后使用合成的新样本改进目标函数。最后组合多个改进后的源分类器和目标分类器进行多源在线迁移学习,并在文本和图像数据集上进行了广泛的实验。实验结果表明,提出的算法不仅能够有效地从多个源域迁移知识,而且能够很好地应对源域和目标域的数据类别分布不均衡的情况。本文研究了不平衡源域和目标域的二值分类问题,多类分类问题更具有挑战性,离线函数和在线目标函数要同时考虑多个类以及其中类别不平衡的情况。未来会继续研究不平衡源域和目标域的多分类多源在线迁移学习问题。
猜你喜欢源域集上类别基于参数字典的多源域自适应学习算法计算机技术与发展(2020年11期)2020-12-04Cookie-Cutter集上的Gibbs测度数学年刊A辑(中文版)(2020年2期)2020-07-25链完备偏序集上广义向量均衡问题解映射的保序性数学物理学报(2019年6期)2020-01-13复扇形指标集上的分布混沌数学物理学报(2017年5期)2017-11-23服务类别新校长(2016年8期)2016-01-10可迁移测度准则下的协变量偏移修正多源集成方法电子与信息学报(2015年12期)2015-08-17论类别股东会商事法论集(2014年1期)2014-06-27中医类别全科医师培养模式的探讨中国中医药现代远程教育(2014年16期)2014-03-01几道导数题引发的解题思考新课程学习·中(2013年3期)2013-06-14聚合酶链式反应快速鉴别5种常见肉类别食品科学(2013年8期)2013-03-11