卢宇 余京蕾 陈鹏鹤 李沐云


摘要:生成式人工智能(Generative Artificial Intelligence)旨在利用人工智能技术自动化生成文本、图像、视频、音频等多模态数据,受到教育领域的广泛关注。其中,ChatGPT系统因其良好的自然语言理解和生成能力,体现出较高的多领域应用潜力。本研究以ChatGPT作为主要对象,基于其四项核心能力,即启发性内容生成能力、对话情境理解能力、序列任务执行能力和程序语言解析能力,探讨在教师教学、学习过程、教育评价、学业辅导四个方面的潜在教育应用。在此基础上,在真实系统中进行了习题生成、自动解题、辅助批阅等教育应用的初步验证。最后,本文进一步探讨了以ChatGPT为代表的生成式人工智能在教育应用中所面临的局限和对教育的启示。
关键词:生成式人工智能;
ChatGPT;
大语言模型;
人工智能教育应用
中图分类号:G434 文献标识码:A 文章编号:1009-458x(2023)4-0024-09
一、引言
2017年7月由国务院印发的《新一代人工智能发展规划》中提出了我国对人工智能发展的战略规划,明确指出要抓住人工智能发展的重大历史机遇(国务院, 2017)。2022年11月,生成式人工智能系统ChatGPT正式发布(OpenAI, 2022),迅速成为教育领域关注和讨论的焦点。生成式人工智能(Generative Artificial Intelligence)指通过人工智能相关技术,自动化生成文本、图像、视频、音频等多类型内容。近年来,随着人工智能技术、算力水平與可获取数据量的提升,生成式人工智能技术依托语言、图像以及多模态大模型(Foundation Model),可以实现较好的内容生成效果(Bommasani et al., 2021),并在传媒、零售、法律、医疗、金融等领域逐步开始提供专业化与个性化内容生成服务。
针对生成式人工智能技术,国内外产业界与学术界都开展了较多的前期研发与投入。国内以百度为代表的AI企业致力于研发基于大模型的生成式人工智能系统,并实现快速落地。例如,ERNIE 3.0(Zhang et al., 2019)是基于知识增强的大语言模型,通过增强学习通识性知识,可进行具备知识可靠性的高质量文本创作;
ERNIE-ViLG 2.0(Ho et al., 2020)作为多模态大模型,可通过输入文字描述,生成具备较好清晰度、可控性与创造性的图像,并基于扩散模型增强图文关键信息获取以及进行降噪过程优化。国外以OpenAI公司为典型代表,在跨模态内容生成、自然语言内容生成等领域,都做出了引领性贡献。例如,DALL·E 2(OpenAI, 2022)跨模态生成系统可依据用户文字描述,生成、扩展、修改和多样性迁移生成原创高清图片;
GPT系列的人工智能系统可以生成文本类内容,逐步逼近实现类人的语言理解与交互能力,并于近期推出了基于大语言模型的多轮对话系统ChatGPT。
ChatGPT系统一经问世,便引发了产业界和学术界的广泛关注,用户规模迅速超过一亿,并在互联网领域迅速实现落地应用。微软“必应”搜索已开始借助ChatGPT,为用户提供结构化整合搜索结果、建议及聊天等功能,显著提升了搜索效率、改善了用户体验。在智能性方面,斯坦福学者依据心智理论测试发现GPT-3.5(ChatGPT的同源模型)可解决100%的意外迁移任务以及85%的意外内容任务,相当于9岁儿童的水平(Kosinski, 2023);
在专业考试方面,ChatGPT及其同源产品可基本通过谷歌L3级软件工程师水平测试、美国执业医师资格考试、美国司法考试中的证据和侵权行为测试、美国宾夕法尼亚大学沃顿商学院MBA运营管理课程考试等。
ChatGPT在文本类内容生成、上下文情境理解等方面所表现出的卓越性能,对教育领域也产生了巨大影响和深刻的启示意义,并可能促进和催化从教育理念到教育实践的深层次变革。长期受技术条件制约的启发式教学与个性化反馈等潜在智能教育应用也开始成为可能。本研究将以ChatGPT为主要研究对象,基于其技术维度的核心能力分析其在教育中的潜在应用,在对部分应用进行初步验证的基础上,探讨其局限性及对教育的启示。
二、ChatGPT概述
(一)历史演变
人工智能领域的研究目标是通过模拟人类智能,使机器能够像人类一样思考和行动。科学家并从模仿人类语言交互的角度提出了著名的“图灵测试”。人工智能发展初期,主要关注知识形式化表征与符号化推理,但一直难以处理复杂多变且具有较强歧义性的人类自然语言。进入21世纪,研究人员开始尝试构建基于统计推断和机器学习技术的自然语言处理模型。虽然这些模型可以提升典型自然语言处理任务的性能,但是仍然难以深入分析和准确生成人类的自然语言。随着深度学习技术的发展,对人类自然语言进行高维分布式表征和隐含特征提取逐渐成为可能,人工智能技术在多项自然语言处理任务上的表现也有了极大提升。2017年谷歌公司提出Transformer(Vaswani et al., 2017)模型,促使自然语言处理模型的参数量得到大幅扩展。在此基础上,研究人员提出了预训练语言模型的概念,即基于大规模语料库并利用自监督学习技术训练语言模型,以提升机器对自然语言的理解能力,并由此开启了自然语言处理领域的大模型时代。
2018年6月,美国OpenAI公司提出了基于Transformer的预训练语言模型(Generative Pre-trained Transformer)GPT-1。GPT-1(Radford et al., 2018)基于自回归理念,采用12个Transformer解码器,构建从左向右单向预测的语言模型,参数量达1.17亿。GPT-1的构建首先基于大型语料库进行无监督的预训练,然后通过有监督的微调技术为下游自然语言处理任务提供解决方案。同年10月,谷歌推出了基于自编码理念的BERT(Bidirectional Encoder Representations from Transformers)模型,基于多层的Transformer编码器,采用从左右双向进行填空学习的方式开展训练(Devlin et al., 2019)。2019年2月,OpenAI发布了GPT-2模型(Radford et al., 2019),其核心理念与GPT-1相似,但采用了更多的Transformer解码器和更大的语料库进行训练,参数量达15亿。GPT-2在多项自然语言处理任务上均有较为出色的表现。同年谷歌进一步提出了T5(Raffel et al., 2019)模型,并在机器翻译与知识问答等任务上表现出更好的性能。2020年5月,OpenAI推出GPT-3(Brown et al., 2020),其参数量相较GPT-2提升了两个数量级,达到1,750亿。参数量的提升使GPT-3在对话生成、文本摘要、机器翻译等任务上展现出了卓越的性能。2022年初,OpenAI在GPT-3的基础上推出InstructGPT(Ouyang et al., 2022),并于同年11月推出其同源模型ChatGPT,在文本生成以及自然语言交互等任务上实现了较为惊人的进步。
(二)相关技术
为实现高质量的生成内容,以ChatGPT为代表的GPT系列系统,主要涉及了五项关键技术和架构。
1. Transformer模型
该模型是ChatGPT等系统的基本组成单元,本质上是一种基于自注意力机制的深度神经网络,主要包含编码器和解码器两部分。编码器主要包括一个自注意力子层和一个全连接前馈神经网络子层:前者计算输入序列中不同位置之间的依赖关系结构并进行特征表示,后者则对新生成的特征表示进行处理,生成最终的表征向量。解码器的基本结构与编码器类似,但针对编码器的输出增加了新的多头注意力层,并加入了掩码设定,以防止解码过程中后继位置信息泄漏。Transformer模型能够高效捕捉序列数据中不同位置之间的依赖关系,并处理任意长度的自然语言序列数据。
2. 基于Transformer的基本架构
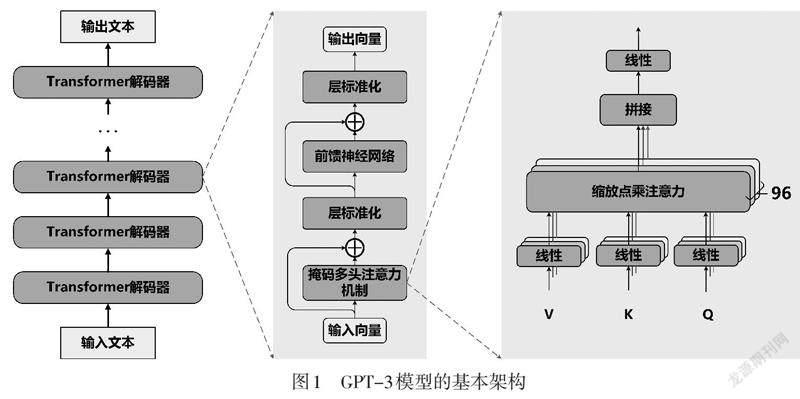
GPT系列系统基于Transformer模型构成其基本系统架构,由于ChatGPT系统的具体技术结构信息目前并没有被完整披露,我们以其前身GPT-3为例进行介绍。如图1所示,GPT-3主要是由96层的Transformer 解码器组成,其中每层的解码器包含掩码多头注意力机制子层和全连接前馈神经网络子层,单词的嵌入维度和上下文窗口长度均进行了扩展,且采用稀疏注意力模式提升运行效率。模型训练的过程基于自回归思想,即给定上文内容预测下文单词或给定下文内容预测上文单词。此外,针对不同自然语言处理任务,GPT-3转换不同格式的文本语料进行模型训练。例如,针对机器翻译任务,训练数据会转换成类似“翻译成英文:他来自中国。He is from China.”格式的文本。这些技术与思想直接帮助GPT系列系统逐步具备了优秀的文本生成能力。
3. 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)技术
该技术是ChatGPT内容生成能力提升的关键(Christinao et al., 2017)。RLHF技术包含三个步骤:第一步是监督式微调,其核心理念是利用符合人类预期的少量标注数据对预训练模型参数进行调整,初步优化文本生成模型;
第二步是构建奖励模型,核心目标是通过对监督式微调生成的多个结果进行人工排序标记,训练奖励函数模型,用于强化学习模型输出结果的自动化评价;
第三步是利用近端策略优化(Proximal Policy Optimization, PPO)算法,结合奖励模型对文本生成模型的结果进行自动评估,并采用强化学习对文本生成模型进行优化,使其最终具备生成符合人类预期的文本的能力(Schulman et al., 2017)。
4. 指示微调(Instruction Tuning)技术
该技术可以辅助ChatGPT等系统生成高质量的文本(Wei et al., 2021)。指示微调是一项语言模型训练技术,通过将预设的指令描述与生成文本相结合,构建训练数据,从而微调文本生成模型的参数。其核心思想是将自然语言处理相关任务转化为基于指令描述的文本生成问题。基于指令描述,可以促使模型理解指令任务,从而生成预期文本。例如,用户输入“判断这句话的对错:三角形的内角和为360度”,其中“判断这句话的对错”是指令描述,指令任务是对“三角形的内角和为360度”进行正误判断,从而生成预期的答案文本“该句话错误”。
5. 思维链(Chain of Thought)技术
该技术通过一系列前后关联的指令,可以辅助ChatGPT等系统完成复杂推理任务(Wei et al., 2022)。语言模型虽然在对人类自然语言表征和建模上取得了显著进展,但在复杂逻辑问题推理上,仍较难达到满意的效果。思维链技术可以针对性地设计模型的指令输入,促使模型将单步骤推理任务拆解为包含多个中间步骤的任务。其中,每一个中间步骤由一个相对简单的指令输入作为引导,其结果代表了多步骤任务的逻辑分析过程。思维链技术可以引导文本类内容生成,辅助模型生成和解决复杂逻辑推理任务。
同时,为解决文本生成过程中产生与用户预期不符的行为问题,例如捏造事实、生成有偏见或有害文本、不遵循用户指示等,ChatGPT等系统的技术研发遵循3H基本原则,即帮助性(Helpful)——模型应帮助用户解决问题、真实性(Honest)——模型不能捏造信息或误导用户、无害性(Harmless)——模型不能对人或环境造成身体、心理或社会性的伤害(Askell et al., 2021;
Ouyang et al., 2022)。
(三)核心能力
上述相關技术与基本原则的科学合理使用,促使ChatGPT等系统在自然语言理解与内容生成方面,显示出以下四项较为突出的核心能力。
1. 启发性内容生成能力
ChatGPT等系统能够基于给定的主题或在多轮对话过程中识别的上下文信息,生成有启发性和创意性的文本,包括诗词、故事、评论等。这些文本不仅可以成为用户的创作素材,也可以在思维广度上为用户带来启发。
2. 对话情境理解能力
ChatGPT等系统能够基于多轮对话中的上下文信息,进行语义理解和推理,捕捉用户意图与对话情境,生成符合逻辑的连贯性回复,为用户带来良好的交互体验。
3. 序列任务执行能力
ChatGPT等系统能够基于用户的序列指令描述,理解指令之间的关联关系,逐步对任务进行推进,完成基于组合指令的复杂任务,从而较好地执行用户给出的多步骤序列任务。
4. 程序语言解析能力
ChatGPT等系统能够根据多种编程语言的语法规则、数据结构、算法构建与编程规范,对代码程序进行结构与算法分析,并根据用户任务需求自动生成符合任务要求的代码程序或错因解析。
上述四项核心能力体现了当前生成式人工智能领域的重要突破和价值,也为其在教育领域的应用提供了诸多可能性。
三、潜在教育应用
基于当前ChatGPT系统所具备的启发性内容生成、对话情境理解、序列任务执行、程序语言解析四项核心能力,我们从教、学、评、辅四个典型教育环节,梳理了不同核心能力可以支持的潜在教育应用,如图2所示。
(一)教师教学
ChatGPT等系统可以为教师教学提供多种形态的帮助和服务。基于启发性内容生成能力,ChatGPT等系统可以依据教师的教学目标生成创作型教学素材,辅助教师设计有创新性的教学活动;
基于对话情境理解能力,ChatGPT等系统可以在课堂教学中充当助教角色,根据当前教学活动情境,为教师提供教学过程的交互式支持;
基于序列任务执行能力,ChatGPT等系统可以依据教学场景与个体教师的教学需求,生成个性化教学方案;
基于程序语言解析能力,ChatGPT等系统可以为教师提供编程课程案例,支持典型问题及其变形的示例性代码生成与说明。
具体而言,在辅助教师生成个性化教学方案的过程中,ChatGPT等系统可以依据教师的教学需求,分步骤生成多种适切的教学设计,为教师在备课过程中提供思路启发与多种备选方案,提升教师的备课效率与授课质量。例如,在中学语文课程《荷塘月色》的教案设计过程中,教师可以首先要求系统制作一份基础方案,包括教学主题、教学目标、教学内容、教学步骤、教学方法、教学评价、教学资源等模块。在此基础上,教师可以继续要求系统增加互动环节,并自动生成朱自清生平小测验、荷塘故事续写等趣味教学活动,供自己参考和选择性补充到教案中。教师也可以要求系统增加课外拓展素材,系统则会从作者的其他代表作品、书信与日记、故乡文化等方面提供参考教学资源。
(二)学习过程
ChatGPT等系统也可以为学习过程提供良好的支持和服务。基于启发性内容生成能力,ChatGPT等系统可以自动生成范文段落示例或启发性思路提示,为学生提供创意写作素材,以人机协同共创方式辅助学生写作;
基于对话情境理解能力,ChatGPT等系统可以识别学生学习情境,结合学科专业知识,为学生提供基于情境的学科知识问答;
基于序列任务执行能力,ChatGPT等系统可以依据学生的学习需求与知识掌握情况,为学生提供动态教学支架与反馈,并优化其学习路径;
基于程序语言解析能力,ChatGPT等系统可以结合学生实际需求与编程任务,为学生推荐相关代码片段与运行解析,帮助其高效理解程序的设计思路与编写方式。
具体而言,在支持学生学科知识问答的过程中,ChatGPT系统可以基于多轮对话,为学生提供从现象分析、知识点讲解、应用影响等多层次服务。例如,系统可以为学生解答“苹果会落地”的物理学原理是地球引力作用,并进一步为学生讲解牛顿运动定律的知识点。如果学生继续提问“这些原理和定律的用途”,系统可以准确理解其问题指向,并从日常生活到航空航天等角度进行解答并做合理扩展。
(三)教育评价
ChatGPT等系统还可以针对性完成教育评价的多项任务。基于启发性内容生成能力,ChatGPT等系统可以为学生作品和答案进行客观点评,引导学生发掘作品优点并提供改进思路;
基于对话情境理解能力,ChatGPT等系统可以对学生的语言表达能力进行评测,通过分析学生对话过程中的词汇、语法、句子结构,以及观点表达与事件描述方式,给出针对性的反馈建议;
基于序列任务执行能力,ChatGPT等系统可以依据测试科目、考察目标、题目类型等组卷需求,自动生成多种备选测试题目,支持教师智能组卷;
基于程序语言解析能力,ChatGPT等系统可以进行高效代码反馈与评价,纠正代码错误并提出优化建议。
具体而言,在为学生提供程序代码评价中,ChatGPT等系统可以通过自动识别程序语言、数据结构、函数类型与代码结构,整体评价典型算法程序的编写正误,并提供关于代码规范性、复杂度等多个维度的细颗粒度反馈与评价。例如,学生输入指令“请对下面这段代码进行评价反馈”并提供代码,系统可以指出该典型算法是否编写正确,并提供针对性建议与改进代码示例。此外,系统还可以从函数命名方式、函数功能注释、参数合法性检验、返回值设计、变量命名等方面提供改进提示。
(四)学业辅导
ChatGPT等系统还可以尝试完成较为复杂和专业的学业辅导任务。基于启发性内容生成能力,ChatGPT等系统可以生成针对性资源和素材,引导学生从不同角度对知识点进行理解,辅助提升学生的知识探究与创新能力;
基于对话情境理解能力,ChatGPT等系统可以依据历史对话信息理解学生的实际辅导需求,结合当前学习内容,为学生提供个性化学习支持;
基于序列任务执行能力,ChatGPT等系统可以针对学生的疑难问题进行分步骤解析,帮助学生理解问题求解的要点与难点;
基于程序语言解析能力,ChatGPT等系统可以生成多维度代码解释,包括参数设置、算法思路、逻辑关系等,帮助学生理解程序内涵与功能,辅助提升学生编程能力。
具体而言,在为学生生成知识探究与创新素材的过程中,ChatGPT等系统除可以生成以事实为依托的素材外,还可以生成基于假设的启发性素材,引导学生从不同维度解构知识,培养学生的思辨能力与探究意识。例如,当学生提问“如果荆轲刺秦王成功了,将会发生什么”,系统可以基于这种假设,为学生分析秦国是否还能统一六国以及中国历史的多种可能发展走向,启发学生对历史问题进行深入思考。
四、教育应用初步验证
本研究從教师教学、学习过程与教育评价三个维度,分别选取题目生成、自动解题与辅助批阅三个具体教育应用,对系统进行初步验证。所选用的系统是2023年2月最新版本的ChatGPT。
(一)题目生成
如表1所示,当用户给出数学应用题生成的指令后,系统可以自动生成符合指令要求且具备合理情境信息的题目及其答案,即通过小明购买水果的情境设置考察乘法与加法的运算。在此基础上,如果给出更改情境的指令,系统会进一步生成小明购买文具的情境并考查相同的数学知识点。最后,如果继续用中文给出“请再出一道类似的英文习题”的指令,系统可以生成描述清晰且考查知识点相同的英文题目,而其具体情境可以有所不同。
经过多轮测试,系统可以持续生成质量和难度均适中的多学科、多情境习题,且大多数生成的题目包含参考答案,便于在教育实际场景中使用。同时,通过给出后续指令,可以对所生成习题的细节性信息进行修改,并可以生成多语种题目。由此可见,在教师教学的应用维度,系统初步具备了依据教学目标生成创作型教学素材的应用能力,可以辅助教师完成包括题目生成在内的多项具体教学任务。
(二)自动解题
如表2所示,用户输入一道涉及加法、除法、百分比等相关知识的数学问题,系统可以自动生成解答内容。在解答内容中,系统首先指出已知条件,即盐的质量为2克,然后解析盐和水的总质量为202克,进而给出质量占比的具体计算公式并计算出正确结果。最后,系统用规范的语句正面回答了该数学问题。
为更好地验证系统的自动解题能力,我们从Multiarith数据集(Roy & Dan, 2016)中選取了50道习题组成测试集。Multiarith数据集是一个多步骤算法数据集,包含600道小学级别的情景类数学题。通过调用InstructGPT相关模型接口进行持续测试,我们发现系统解题的平均准确率约为68%。该结果已经明显高于GPT-3的准确率,且解答错误的原因大多是源于对情境中所需常识性知识的误判。我们进一步对系统解题过程中的推理文字进行分析,发现所生成的文字合理且易懂,大幅度超过了之前GPT-3的逻辑表达能力。例如,GPT-3生成的解题思路通常会存在错误的因果关系和推理,但ChatGPT系统已经可以给出完整清晰的解题逻辑,且在关键步骤上均配有计算公式和描述。
通过以上试验,我们可以初步验证系统已经具有较好的自动解题功能,所生成的解题结果具有一定的准确性与可读性,其逻辑表达清晰且形式丰富。由此可见,在学习过程维度,系统已经初步具备了完成个性化学科知识问答与支架式教学反馈等教育应用的能力。另外需要指出的是,对于具有较为复杂情境的题目,ChatGPT系统自动解题和反馈能力还有待提高。
(三)辅助批阅
如表3所示,用户输入一道完整的题目及其错误解答,系统可以根据用户指示,自动判断答案正误并给出具体反馈,从而完成辅助批阅的基本任务。在生成的辅助批阅文本中,系统首先明确给出了正确与否的判断,然后用合理准确的语言给出了错误原因的分析,即指出桃树数量“不是仅仅是苹果树数量的1/5”,而应是“苹果树数量的1/5加上苹果树数量”。在此基础上,系统可以继续自动给出合理的解题过程与正确的答案。
我们进一步对题目内容和答案进行更改并测试,发现系统可以持续输出类似的辅助批阅结果。由此可见,系统已经具有题目答案正误判断和错因分析等基本功能,即具备了对学生作品和习题答案进行客观点评和判断的能力。这种诊断性评价能力具有很高的教育应用价值,是构建全流程自动化教育评价服务的关键性技术保障和基础。
五、局限与启示
(一)局限与问题
以ChatGPT为代表的生成式人工智能系统仍然面临诸多局限。首先,系统仍然难以充分理解信息和分析信息内在的逻辑关系,因此很容易生成不合理的内容或者犯事实性的错误。例如ChatGPT会非常自然地回答诸如“诸葛亮是如何打败秦始皇”或“林黛玉初见曹雪芹的情景”,所给出的错误且荒谬的答案体现了该技术并不能像人类一样完整理解知识体系与内在联系。这种事实性的错误也容易误导不具备专业知识或相关常识的学习者,引起学习迷航与认知障碍。
其次,生成式人工智能的过程仍然是黑箱,所生成的内容不具备可解释性与明确的依据。例如让ChatGPT 写出“低时间复杂度的字符串匹配”代码,即使所生成的长段代码可以运行且结果看似正确,但由于其中代码生成的来源和算法依据都不清晰,代码中细微的逻辑错误或步骤冗余也难以精确识别,因此难以直接应用于重要的课程实践和高利害的考试任务中。
另外,生成式人工智能在中文语境和文字上的理解和表达能力总体上要弱于英文。例如对于“苹果比梨多1/6”这样含义的语句,ChatGPT经常会生成“苹果是梨的1/6”或“苹果是梨的1/6倍”这样的错误或不符合中文语言习惯的表述。这种能力差距源于预训练语料中以英文为主的现实情况,也因此可能导致非英语母语的学习者理解困难甚至理解错误。
同时,生成式人工智能技术也可能被恶意利用,造成较为严重的安全隐患。例如,可以用多步提示的方式,引导系统给出“如何入室盗窃”或“如何制造伤人工具”这类问题的危险答案。这些危险信息如果被各学段学习者获得和传播,会带来较为严重的青少年问题和社会危害。另外,生成式人工智能技术的数据源本身复杂且庞大,其生成的内容可能有知识产权问题,且容易产生法律风险。例如在模型训练和微调过程中,ChatGPT等产品所需的大规模数据集不可避免要涉及各类受法律保护的知识产权类数据,这些未经著作权人授权的数据的使用以及所生成的相应内容,存在侵犯他人著作权或专利权的风险。
最后,需要指出的是,以ChatGPT为代表的生成式人工智能虽然在教育领域有广泛的应用前景,但并非在所有场景都有重要应用潜力和作用。例如在教育智能化管理与服务中,通常需要依靠准确的数据支撑和透明的决策模型,很难简单依赖“黑箱式”的生成式人工智能技术。另外,生成式人工智能的模型训练、测试与下游任务适配,均需要较大规模的计算资源和存储资源进行支持,这种高成本对于相当一部分教育业务是难以承受的。因此,人工智能生成内容技术的教育应用范围和场景也有一定的局限性,应避免在教育领域盲目推广和普及。
(二)启示与展望
1. 推进教育理念变革
虽然以ChatGPT为代表的人工智能生成内容仍然存在诸多局限,但其所具备的核心能力已开始对教育理念产生直接影响和启示作用。我国现阶段教育仍重视通过大量记忆、识别和练习而获取知识,忽视通过分析思考而发现并掌握知识的方法与技能。生成式人工智能技术已逐步显现出高效积累知识与合理使用知识的基本能力,可以预见将替代和超越只能获取和存储知识的低阶思维脑力劳动者。因此,教育应该更加侧重于培养学生的高阶思维能力,尤其是跨学科多元思维能力、批判性思维能力与创造性思维能力。只有具备较强的跨学科多元思维能力,学生才能认识和区分现实世界的复杂问题和情境,并最终完成人工智能难以应对的实际任务;
只有具备良好的批判性思维能力,学生才能对知识和技能有超越人工智能模型的深入理解和分析,并充分认识到人工智能技术的局限及其工具属性;
只有具备一定的创造性思维能力,学生才能充分挖掘和发挥自身在特定领域的创新潜力和作用,避免被智能机器在专业领域简单替代。同时,新技术条件下的教育,需要加速教师队伍的观念转变,让一线教育工作者充分认识到技术变革所带来的社会需求变革,充分调动教师在教育理念变革过程中的积极性和创造力。
2. 创新教学方式与内容
在重视高阶思维能力培养的教育理念驱动下,生成式人工智能技术与产品对教学方式与教学内容的影响也会逐渐显现,并扮演不同的角色和发挥不同的作用。在教学方式上,需要鼓励教师积极创新课堂教学方式,將相关技术纳入不同学科的教学过程中,丰富课堂活动内容及其趣味性。例如,通过设置具备良好交互能力的人工智能助教,提供实时机器反馈甚至人机辩论环境,鼓励学生与机器助教开展共创性学习,持续性获取所需的个性化学习信息与资源,从而培养学生高阶思维能力和自主学习能力。在教学内容上,需要积极调整不同学科的培养目标和教学要求,更加强调学科核心素养导向的教学内容设置。例如当前人工智能生成内容技术已经具备良好的多语言代码生成与调试能力,初级程序员的社会分工可能将逐步消失。因此,对于基础教育与职业教育阶段的编程类教学,需要更加强调计算思维、人工智能素养与算法思维的培养,减少对于程序语言中语法细节的记忆性学习。
3. 鼓励教育与技术互促共进
人工智能生成内容相关技术的演进速度非常快。以GPT系列为例,从第一代GPT-1到目前的ChatGPT经历了四代更新,每一代的性能都有明显提升,但更新换代的时间不足五年。因此,可以预见更加智能化和人性化的生成式人工智能技术与产品将会在短期内出现,其在自然语言处理等任务上的性能将进一步提升,也将具备更优秀的内容理解、生成与泛化能力。因此,教育需要积极适应人工智能技术的快速发展,对其持有更加开放和包容的态度,鼓励教育工作者秉持技术向善理念,研究和使用相关技术和工具,协作完成各类教学任务。同时,需要充分认识这类新技术不再是“拍照搜题”或“换脸软件”,而可能成为未来教育的重要组成部分并对教育领域具有深刻的变革性意义。另外,教育领域也需要高度关注生成式人工智能技术的潜在安全与伦理风险,针对教育领域的应用场景,推进制定相关法律法规,形成技术与教育双螺旋式的互促共进。当通用人工智能已经逐步接近人类社会,教育作为人类文明进步的基石,应该从容应对挑战且充满自信。
[参考文献]
国务院. (2017-07-20). 新一代人工智能发展规划(国发〔2017〕35号). 中华人民共和国中央人民政府网站. http://www.gov.cn/zhengce/content/2017-07/20/content5211996.htm
Askell, A., Bai, Y., Chen, A., Darin, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Kernion, J., Ndousse, K., Olsson, C., Amodei, D., Brown, T., Clark, J., ... Olah, C.(2021). A general language assistant as a laboratory for alignment. arXiv preprint arXiv, 2112.00861.
Bommasani, R., Hudon, D. A., Adeli, E., Altman, R., Arora, S., Arx, S., Bernstein, M., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J., Demszky, D., ... Liang, P.(2021). On the opportunities and risks of foundation models. arXiv preprint arXiv, 2021:2108.07258.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., ... Amodei, D.(2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D.(2017). Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
Devlin, J., Chang, W., Lee, K., & Toutanova, K. (2019). Bert:
Pre-training of deep bidirectional transformers for language understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:
Human Language Technologies, 4171-4186.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840-6851.
Kosinski, M. (2023). Theory of Mind May Have Spontaneously Emerged in Large Language Models. arXiv preprint arXiv, 2302.02083.
OpenAI. (2022-04-06). DALL·E 2. OpenAI. https://openai.com/dall-e-2/OpenAI. (2022-11-30). ChatGPT:
Optimizing Language Models for Dialogue.OpenAI. https://openai.com/blog/chatgpt/
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., ... Lowe, R.(2022). Training language models to follow instructions with human feedback. arXiv preprint arXiv, 2203.02155.
Roy, S., & Dan, R. (2015). Solving general arithmetic word problems. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 15, 1743-1752.
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I.(2018). Improving language understanding by generative pre-training.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I.(2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, Wei., & Liu, P. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21, 1-67.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O.(2017). Proximal policy optimization algorithms. arXiv preprint arXiv, 1707.06347.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
Wei, J., Bosma, M., Zhao, Y., Guu, K., Yu, W., Lester, B., Du, N., Dai, A. M., & Le, V. (2021). Finetuned language models are zero-shot learners. International Conference on Learning Representations, 10.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 36.
Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE:
Enhanced Language Representation with Informative Entities. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 1441-1451.
基金項目:本文系北京市教育科学“十四五”规划2021年度重点课题“人工智能驱动的新一代智能导学系统构建研究”(课题编号:CHAA21036)的研究成果。
作者简介:卢宇,北京师范大学教育学部未来教育高精尖创新中心副教授。
余京蕾,北京师范大学教育学部教育技术学院博士研究生。
陈鹏鹤,北京师范大学教育学部未来教育高精尖创新中心讲师(通讯作者:chenpenghe@bnu.eu.cn)。
李沐云,北京师范大学教育学部教育技术学院硕士研究生。