赵晋巍,刘晓鹏,罗 威,程 瑾,毛 彬,宋 宇
大数据时代数据分析工作通常需要处理不同来源、不同领域的数据,这些数据呈现出不同的模态[1],如视频、图片、语音,以及工业场景下的传感数据和红外、声谱等。多模态数据是指对同一个描述对象通过不同领域或视角获取到的数据,而把描述这些数据的每一个领域或视角叫做一个模态[2]。顾名思义,多模态数据融合的研究内容就是这些不同类型的数据的融合问题,即利用计算机进行多模态数据的综合处理。
Contrastive Language-image Pre-training(CLIP)模型是一个在各种“图像-文本”对上进行训练的神经网络[3]。它是一种基于对比学习的多模态模型,通过图像和它对应描述文本的对比训练,达到学习两者匹配关系的目的。作为多模态训练的结果,CLIP 模型可用于查找最能代表图像的文本片段,或根据给定文本查询最合适的图像,甚至可以基于文本对图像进行分类[4]。CLIP 模型打破了自然语言处理和计算机视觉两大门派“泾渭分明”的界限,实现了多模态的AI 系统,融合了不同模态进行检索,这使CLIP 模型在图像和文本搜索中非常有用。笔者开展了多年的开源军事相关图片资源的本地化建设,内容涵盖装备使用、军事行动、保障维修等方面,共搜集到图片30 余万张,这些图片资源大多带有原生的描述文本,而且某些重要的图片已进行了人工分类和标注,因此具备开展图片深度挖掘处理的资源基础。在图片资源发现上,传统的图片检索技术采用文本匹配模式,即通过搜索关键词与图片标题、描述信息进行精确或模糊匹配。而对于描述信息缺失的图片或标引错误的图片来说,文本匹配模式无能为力,并且也无法进行以图搜图,如通过模糊图片找到更高清图片,或通过图片找到相似前景目标物的图片。基于此,本文通过CLIP 模型的再训练,开展多模态搜索的相关应用研究,包括军事领域内图片资源的以文搜图和以图搜图。
1.1 CLIP 模型概述
以往的计算机视觉(Computational Vision,CV)模型通常被训练用于预测有限的物体类别(如ImageNet 数据集中有1 000 个分类标签)。这种严格的监督训练方式限制了模型的泛化性和实用性,因为这样的模型通常还需要额外的标注数据来完成训练时未曾见过的图像(视觉)“概念”[5]。2021 年初,OpenAI 推出了AI 视觉模型CLIP(图1),该模型以4 亿对网络图文数据集(Web ImageText,WIT)作为训练集,将文本作为图像标签进行训练。当进行下游推理任务时,只需要提供和图像语义对应的文本描述,就可以进行零样本(Zero-Shot)推理迁移。经过庞大的数据集训练,CLIP 模型在图文识别和融合上展现了很高的表现力。
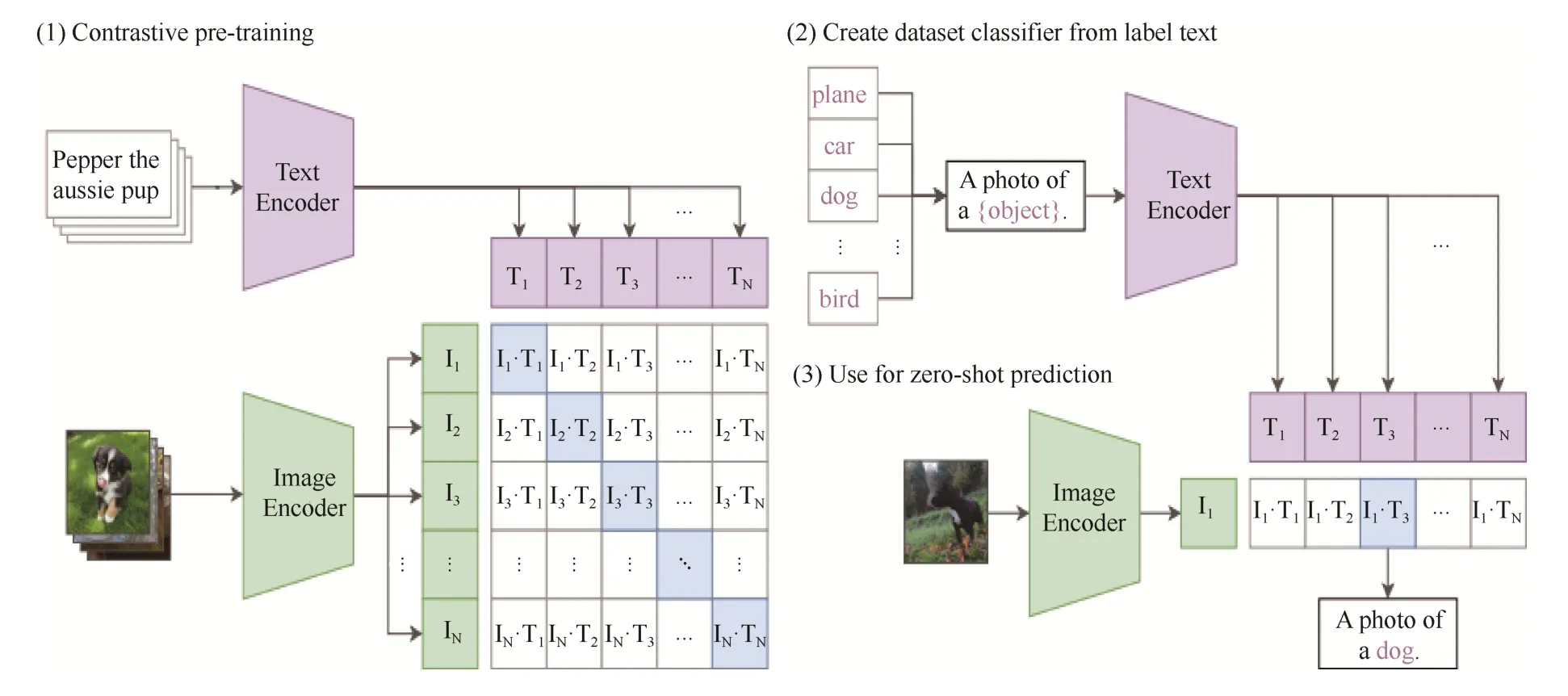
图1 CLIP 模型的框架结构
1.1.1 预训练
CLIP 模型联合训练图像编码器(如ResNet50)和文本编码器(如BERT),以预测一批图像和文本的正确配对。假设给定一个包括N个“图像-文本”对的数据集,就能得到n个图片的特征和n个文本的特征,CLIP 模型的训练目标是判断在一个数据集中N×N个“图像-文本”对中的哪一对是匹配的。为此,CLIP 模型通过线性投影将每个编码器的表示映射到多模式嵌入空间,通过联合训练图像编码器和文本编码器来最大化数据集中的n对匹配的图文特征余弦相似度,同时最小化N2-N个错误对的余弦相似度,从而达到对比学习的目的。此外,CLIP 模型在这些相似度上用对称的交叉熵损失进行优化。
图1 中的预训练对比学习(Contrastive Pre-training)部分,N×N矩阵对角线上配对的n个“图像-文本”对都是正样本,矩阵中非对角线上的N2-N个元素都是负样本,有了正负样本,模型就可以通过对比学习的方式去训练,因此不需要任何手工标注。
1.1.2 Zero-Shot 的推理
在计算机视觉中,Zero-Shot 学习通常指在图像分类中对没见过的对象类别进行泛化的研究[6]。CLIP 模型的预训练方式是预测一张图片和一段文本在其数据集中是否匹配。为了实现Zero-Shot 推理,将每个数据集中所有类的名称作为潜在文本配对的集合,并用CLIP 模型预测最可能的“图像-文本”配对,即把分类转换为检索问题。
具体到图 1 中的提取预测类别文本特征(Create dataset classifier from label text)和Zero-Shot推理预测(Use for zero-shot prediction)部分,首先计算图像的特征嵌入和可能分类集合的特征嵌入,然后计算这些嵌入的余弦相似度,然后用一个温度参数进行缩放,并通过Softmax 函数将其归一化为概率分布。预测层是具有L2 归一化输入、L2 归一化权重、无偏差和温度缩放的多项式逻辑回归分类器。图像编码器计算图像的特征表示,而文本编码器基于视觉类别的文本来生成线性分类器的权重。如对ImageNet[7]数据集上的Zero-Shot 迁移,文本编码器需要生成1 000 个类别的表示,而且用每张图片的特征表示和这1 000 个文本表示进行匹配,最接近的文本特征对应的类别就是图像属于的类别。
另一方面,预训练之后得到的文本和图片的特征是没有分类标签的,CLIP 模型使用类似“A photo of a {label}.”模板生成分类文本。该方法比只使用标签文本的Baseline 性能有所提高,在ImageNet数据集上的准确率提高了1.3%[5]。
1.1.3 CLIP 模型的实验性能
图2 显示了CLIP Zero-Shot 推理与ResNet101模型在不同的数据集(如ImgeNet 原生数据集及其筛选出的素描、动漫等数据集和构造的包含很多对抗样本的数据集)测试结果的对比,随着数据集难度的增加,ResNet101 的分类精度在一直下降,而CLIP 模型却并没有随着数据集难度的加大而出现性能下降等情况。因此与标准ImageNet 模型相比,CLIP Zero-Shot 推理对分布偏移更具鲁棒性,比基于ImageNet 数据集的标准有监督训练模型要好得多。

图2 CLIP 模型的鲁棒性实验结果
1.2 CLIP 模型应用研究现状
有学者提出了利用文字表述来对图像进行编辑的模型,即StyleCLIP 模型[8]。该模型借助CLIP 模型的“文本-图像”相关性能力和StyleGAN 的图像生成能力,通过文本驱动生成图像。StyleCLIP 模型提出了隐空间优化(Latent Optimization)、隐空间映射(Latent Mapper)和全局方向(Global Directions)3 种实现方式,每种方式都可以实现编辑图像的目的,只是在实现细节上有所区别。
Google 的研究人员提出了ViLD 模型[9],这是一种通过视觉和语言知识蒸馏的训练方法。ViLD 模型由文本嵌入(ViLD-text)和图像嵌入(ViLD-image)学习器两部分组成。它将CLIP 图像分类模型应用到了目标检测任务上,在新增类别推理上Zero-Shot超过了有监督训练的方法。
腾讯的研究人员提出了CLIP2Video 模型[10],以端到端的方式将图像语言预训练模型转换为视频文本检索模型,即将CLIP 模型的“文本-图像”对扩展到“文本-视频”对,以解决视频文本检索问题。该模型基于CLIP 捕获的空间语义,主要通过时间差分块(temporal difference block,TDB)和时间对齐块(temporal alignment block,TAB)两个模块将图片语言预训练模型转换为视频文本检索。这两个模块是为了捕获视频帧的时间关系和视频语言关系而设计的。对时间差分块,本文在序列中加入图像帧的差分来模拟运动变化;
对时间对齐块,本文将视频序列和文本序列对齐到相同的空间,以增强视频片段和短语之间的相关性。
有学者提出了将跨模态注意力对比的“语言-图像”预训练模型(CMA-CLIP)[11]用于图文分类任务,还提出了序列注意力(sequence-wise attention)和模式注意力(modality-wise attention)两种跨模态注意力,以有效地融合来自图像和文本对的信息。CMA-CLIP 模型在多任务分类的MRWPA 数据集上表现优异。
如前文所述,CLIP 模型可用于图像分类、目标检测、视频理解、图像编辑等领域。由于CLIP是一种在巨量图像和文本对上预训练的神经网络,我们可根据自身资源特点开展针对性的再训练,以提高自身资源检索或分类的精度。作为这种多模态训练的结果,CLIP 模型可用于查找最能代表图像的文本片段,或根据给定文本查询最合适的图像,图文检索(以文搜图、以图搜文、以图搜图等)是CLIP 模型最直接实现的应用。
2.1 构建训练样本和再训练
CLIP 模型库中有RN50、RN101、ViT-B/32、ViT-B/16 等9 个模型,本文主要针对ViT-B/32 模型进行了再训练。ViT-B/32 模型用于编码图像特征,包括图像分辨率、嵌入维度、Transformer 的层数、Transformer 模型头数等输入维度和输出维度,参数配置表如表1 所示。

表1 ViT-B/32 模型的参数配置
训练样本主要从自建的军事相关图片数据集中进行构建,样本元数据字段包括图片标题、图片描述、分类、图片路径等,数据格式保存为JSON格式。
训练过程主要包括以下3 个步骤。
第一步:通过DataLoader 函数加载一个批次(batch)的N个“文本-图像”对。将N个文本通过文本编码器(Text Encoder)进行文本编码,定义文本编码器中每条文本编码为长度为dt的一维向量,那么这个批次的文本数据经Text Encoder 输出为[T1,T2,…TN],维度为(N,dt)。类似地,将N个图像通过图像编码器(Image Encoder)进行图像编码输出为[I1,I2,…IN],维度为(I,di)。
第二步:训练样本T1,T2,…TN和I1,I2,…IN是一一对应的,将这个对应关系记为正样本;
将原本并不对应的“文本-图像”对标记为负样本,由此便产生N个正样本,N2-N个负样本,用以训练文本编码器和图像编码器。
第三步:计算Ii与Tj之间的余弦相似度Ii·Tj,用来度量文本与图像之间的对应关系。余弦相似度越大,说明Ii与Tj的对应关系越强,反之越弱。即通过训练文本编码器和图像编码器的参数,最大化N个正样本的余弦相似度,最小化N2-N个负样本的余弦相似度。优化目标函数的公式为:
2.2 多模态搜索系统核心流程的设计
基于存有30 余万张图片的开源军事相关图片数据集,设计开发了具有以文搜图和以图搜图功能的服务原型系统,核心流程如图3 所示。
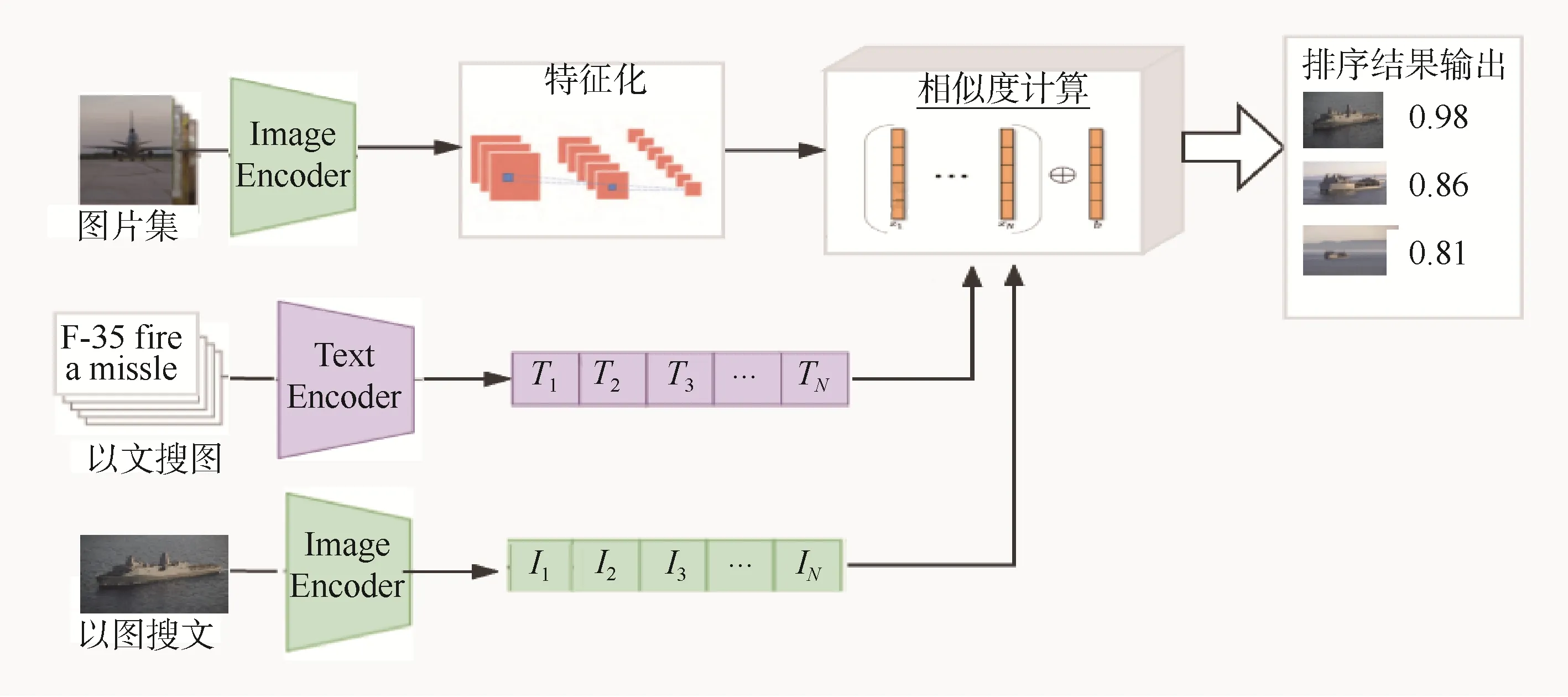
图3 多模态搜索服务原型系统流程
多模态搜索服务原型系统主要包括以下3 种主体功能。一是图片数据集预处理,将30 余万张图片进行向量化预处理,加载CLIP 模型并特征化图片向量,形成图片集特征化矩阵并缓存。二是通过文本编码器进行查询文本的特征化,通过图像编码器(ViT)进行查询图像的特征化。三是查询匹配,通过线性映射层将文本和图像特征进行嵌入,映射到相同特征维度,同时进行L2 标准化。将查询文本或图像与图片集特征化矩阵进行余弦相似度计算,并根据相似性对结果进行排序。
2.3 多模态搜索服务系统实现
服务原型系统采用Django+Redis缓存框架开发,系统分为以文搜图和以图搜图两个搜索功能区。
图4 是以“Aerial refueling”作为搜索文本进行场景搜图的效果展示。图4 显示,系统返回的前160个结果集合中仅有6 张图片没有明显的空中加油动作,证明系统以文搜图的准确率还是非常高的。图5 为检索“air force”文本的返回结果,检出了喷涂有“air force”文字的美军机和美空军标志,未来可在目标文字光学字符识别(Optical Character Recognition,OCR)及目标检测上开展深入研究应用。

图4 以文搜图的场景搜图效果展示

图5 以文搜图的OCR 效果展示
图6 是以图搜图的效果展示。上传图片为一张无人机照片,通过以图搜图,不仅可以获得相关类似甚至更高清的图片,同时基于图片库还可以得到该图片丰富的背景信息,从细览页得知该无人机是美海军测试的MQ-25 无人加油机。

图6 以图搜图的效果展示
目前,多模态检索、预训练模型受到越来越多的关注,学界也兴起了关于多模态检索未来趋势和发展的大讨论,CLIP 模型在多模态搜索工具的研究上迈出了第一步,实现了在大规模数据的情况下模型对图像和文本的学习能力的大幅提升。本文通过收集的大规模军事相关图片数据集,借助CLIP模型,设计开发了具有以文搜图和以图搜图功能的多模态搜索服务原型网站。在实际测试中发现,CLIP 模型对一些抽象文本也能够检索出不错的结果。下一步将围绕针对军事装备相关图片的模型微调,以及在军事装备及事件分类、目标检测、人物轨迹跟踪等方面开展分析和应用研究。
猜你喜欢编码器模态分类基于BERT-VGG16的多模态情感分析模型成都信息工程大学学报(2022年4期)2022-11-18融合CNN和Transformer编码器的变声语音鉴别与还原网络安全与数据管理(2022年1期)2022-08-29多模态超声监测DBD移植肾的临床应用昆明医科大学学报(2022年3期)2022-04-19分类算一算数学小灵通(1-2年级)(2021年4期)2021-06-09分类讨论求坐标中学生数理化·七年级数学人教版(2019年4期)2019-05-20基于FPGA的同步机轴角编码器成都信息工程大学学报(2018年3期)2018-08-29数据分析中的分类讨论中学生数理化·七年级数学人教版(2018年6期)2018-06-26教你一招:数的分类初中生世界·七年级(2017年9期)2017-10-13应用旋转磁场编码器实现角度测量西安工程大学学报(2016年6期)2017-01-15车辆CAE分析中自由模态和约束模态的应用与对比广西科技大学学报(2016年1期)2016-06-22