李 然,邱 皖,娄 岩
(1.大连海洋大学 信息工程学院,辽宁 大连 116023;
2.中国医科大学 智能医学学院,沈阳 110122)
冠心病监护室(CCU)是重症监护室(ICU)的一部分,主要关注心脏病患者,病情通常严重威胁到患者的生命。CCU先进的设备和持续的监护保证了病人的病情可以得到有效监测,这些监测数据对医生制定合适的干预措施至关重要。同时,在CCU可以得到患者的生命体征、检查结果和处方等各种数据,为使用CCU数据决策提供了较好的支持。
死亡预测是CCU的医务人员进行治疗决策的重要的依据之一。作为重症监护的一部分,各种危重评估系统用于CCU临床预测,包括急性生理学和慢性健康评估(APACHE)[1]、简化急性生理学评估(SAPS)[2]和死亡率概率模型(MPM)[3]。这些评估模型依赖患者在入住CCU后最初几个小时内获得的生理测量值(例如24 h),测量值与规定正常值的偏差越高,死亡风险越高。医生制定治疗方案时会考虑这些评估值。然而,这些传统的基于统计的模型存在一些局限性,包括:①用于预测的数据取自于静态数据;
②模型更新周期长;
③没有利用多模态数据。
为了克服这些局限性,近年来,机器学习方法,如决策树[4-5]和支持向量机(SVM)[6-8],被用来预测CCU死亡风险。由于这些数据驱动的预测模型的存在,建立基于局域ICU数据的个性化评估系统成为可能。而基准的机器学习方法很难充分利用ICU数据的时间性和异构性。最近,有研究人员引入深度学习技术来解决这些问题,将具有时间属性的多模态ICU事件输入到不同的神经网络,如传统神经网络(CNN)[9-10]和递归神经网络(RNN)[11-13],生成低维的特征表示。这些特征包含了患者历史信息的核心特征,对提高死亡风险预测很有帮助。
已有的ICU相关研究中,逻辑回归、支持向量机、朴素贝叶斯等方法适用于小规模和特定数据集,CNN、CNN-NHANES、GaborCNN、CNN-LSTM等方法需要大量数据进行训练,且训练出的模型可解释性较差,CWT-CNN允许样本有较大的的缺损、畸变,运行速度快,模型具备一定可解释性。
目前大多数的针对ICU的死亡预测研究更加重视结构化数据,很少结合患者的CT影像和心电图这样的非结构化数据研究。但由于CCU主要关注心脏病患者,必须备有做心电图的长期监护措施,所以CCU患者更需要关注心脏的检测数据心电图(ECG)和心脏超声报告(ECHO)数据,这在CCU患者的死亡率预测中起着至关重要的作用。
本研究提出了一种动态预测CCU患者死亡风险的多模态融合方法,主要分析现有的CCU中危重风险评估系统的局限性,指出了在死亡预测中探索多模态数据机器学习方法的必要性。同时,从2个维度对CCU多模态数据进行了系统分类。在此基础上,对不同类型的数据采用不同的融合方法,加入了时间维度进行预测。
现有的临床多模态融合研究主要集中在医学影像上,如核磁共振(MRI)、计算机断层扫描(CT)和X射线。然而,CCU数据的形式远不止这些。因此,本研究从2个维度进行系统分类,以展示数据的多样性,如图1所示。
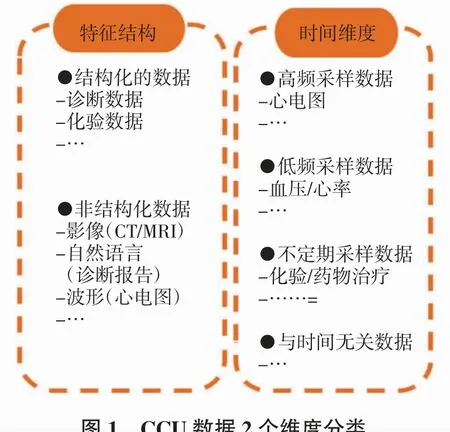
图1 CCU数据2个维度分类Fig.1 Classification for CCU data from two orthogonal dimensions
图1中,第1个维度将数据分为结构化数据和非结构化数据。基准的机器学习方法大多采用结构化数据进行建模,如年龄、性别和检查数据等,很少采用医学影像、自然语言报告和心电图这样的非结构化数据。第2个维度是关于时间属性。数据可归纳为4类:高频采样数据、低频采样数据、不定期采样数据及时间无关数据。在不同的时间维度上整合这些数据是本研究着重解决的问题。
将患者在CCU中住院期间发生的临床事件定义为si,观察的时间为长度Ti,临床事件s_(i)表示为三元组eji=(k,v,t)。k和v分别是事件的类型和值。k和v对应一个时间记录t,在这里t是相对于患者进入CCU的时间间隔。例如,(pulse,56,5 h)表示患者入院后5 h脉搏为56。对于与时间无关的事件,设置t为NULL。
动态死亡风险预测任务定义为:对于每个CCU的临床事件si,给定一个预测时间戳T(Tmin≤T≤Ti),根据事件顺序预测患者是否会在未来24 h内死亡(从T到T+24 h),Tmin是预测中收集数据的最小时间跨度。在本研究中,每小时进行一次预测。
在CCU数据的各种形式中,非结构化数据很少用于死亡风险预测。主要障碍是很难将这些数据与用于预测的结构化数据相集成。本研究的关键技术是对不同的非结构化数据使用不同的方法来提取不同的结构化特征,这些特征可以与结构化数据融合。以MIMIC-III数据集为例,有2种典型的非结构化数据:文本形式的ECHO和波形形式的ECG。这些数据对反映CCU患者的心脏状态很重要[14]。
3.1 文本数据
对于自然语言处理,深度学习方法已经达到了较成熟的水平。本研究采用经典的处理路线,包含3个步骤来从超声报告ECHO中生成结构化特征[15]。
(1)词级嵌入。假设一个单词可以用上下文单词来表示,为每个单词生成嵌入。单词嵌入是一组包含丰富语义信息的低维向量[16]。
(2)报表级嵌入。基于单词级嵌入,构建一个CNN为每个报告生成嵌入,如图2所示。在CNN训练中,解决两个问题:①是冠心病还是其他功能性心脏病;
②是否住院死亡。多任务学习不仅有助于避免过拟合,而且有助于提取更丰富的特征。使用不同大小的多个卷积核来捕获各种词序、语法和语义信息。从池层导出的向量形成报表级嵌入。

图2 CNN和文本数据聚类Fig.2 CNN and clustering for textual data
(3)聚类。虽然报表级嵌入对于表示超声报告ECHO是有效的,但是很难将它们与其他结构化特征融合以进行预测。本研究在这些嵌入上使用K均值将它们分到几个集群中,使CCU的每个超声ECHO报告都可以转换为一个热特征。
3.2 波形数据
心电图作为反映心脏生理活动的高频波形数据,在CCU患者的死亡风险预测中具有很大的潜在价值,信号处理在心电分析中起着重要的作用,结构化特征可以通过成熟的技术进行提取。本研究采用文献[17]中提出的特征提取流程对心电数据进行处理。首先计算整个信号的频谱图以去除噪声,然后从心电信号中提取形态学特征、心率变异性(HRV)特征、频率特征、统计特征和一些噪声检测特征[18]。
3.3 多模态融合
大多数常用分类器没有考虑时间因素对于预测的有效性。为了在模型中加入时间信息,本研究构造了2种与时间相关的特征集,使分类器具有时间属性。一个特征集来自事件序列{eji}T-1h≤eji.t≤T),表示预测时间戳最近(1 h)发生的事件;
另一个特征集来自事件序列,{eji}0≤eji.t≤T-1h)代表更早发生的历史事件。时间属性的事件中既包括定期测量的生命体征,也包括不定期采集的化验结果,例如白细胞计数(WBC)和钾含量。这些事件序列全部来自病人的历史数据收集窗口,时间段为进入CCU后的前24 h。一个事件序列在数据收集窗口内会存在多个观测值,而且不同事件序列的采样频率不相同[19]。为了解决事件序列采样不均匀的问题,基于时间采样窗口对事件序列进行重采样,例如每小时采样一次,这样数据收集窗口可分成24个时间采样窗口。在一个时间段内若仍然存在多个观测值,则计算出现在同一个时间段内的所有观测值的统计量,以此作为该时间段的特征表示。根据每个事件序列的特性选择合适的统计量[20]。例如,尿量在某个时间段的表示是所有尿量的总和。将全部事件序列的特征表示向量拼接起来,即可得到时间序列数据的特征表示向量。对于临床数据中的非事件序列,如离散型变量,则采用one-hot方法来表示。最终,将临床数据中所有变量的表示拼接,得到病人的表示,再输入到XGboost中,进行未来的死亡风险预测。
对具有不同时间属性的事件使用不同的策略:
(1)对于波形事件(高频或低频),使用上述方法生成特征。
(2)对于不定期采样的事件,使用最近特征集的最新值和早期特征集的平均值。
(3)对于与时间无关的事件,将它们插入到2个特征集中。
4.1 数据源
MIMIC-III是一个可自由访问的数据库,包含5种不同类型的重症监护室的多模态数据:CCU、心脏外科康复室(CSRU)、内科重症监护室(MICU)、外科重症监护室(SICU)和创伤外科重症监护室(TSICU)。数据种类包括人口统计、生命体征、化验数据、药物信息等,这些数据来自4万多名危重患者,时间跨度超过10 a。本研究从实验数据集中提取了CCU的数据。MIMIC-III数据集和CCU子集的简要统计数据如表1所示。
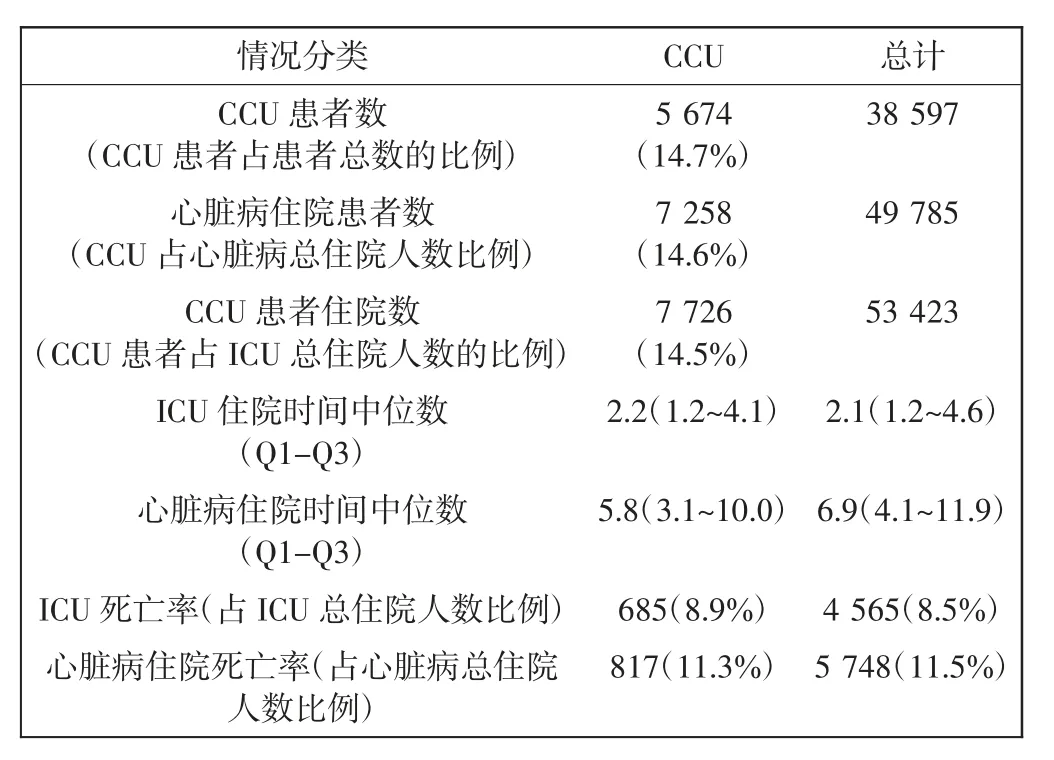
表1 MIMIC-III数据集的统计Tab.1 The statistic of MIMIC-III dataset
4.2 实验设计
实验的目标是基于病人在进入CCU后的前24 h的历史数据,预测未来24 h内是否会死亡。实验的输入是从数据收集窗口中采集的非时间序列数据、临床时间序列数据和ECG波形监测信号数据,标签是病人在未来24 h内的死亡情况。在清洗后(删除参考价值不高、缺失较多的数据)的数据中提取出患者在CCU期间死亡风险预测模型中所需的43个变量后进行数据归一化后拼接,得到病人的特征表示,使用XGBoost将多模态数据融合,进行预测模型的学习,结合这些变量进行患者死亡风险的预测,最后输出患者的预测类别(存活/死亡)。通过设置对照实验,验证本文所述方法性能的优越性。
4.2.1 患者数据集定义及样本特征选取
本研究定义最小观察窗Tmin=6 h,最长观察窗Tmax=24 h。在实验中。由于患者在整个CCU停留期间,ECG并非总是连续记录的,因此将每个患者在CCU停留时间分割成几个事件序列,对一次就诊中的所有事件向量进行分组,以确保每个序列包含超过6 h的连续ECG数据。此步骤的主要原因是减少模型输入数据,提高计算效率。
(1)患者数据集定义:选取第一次进入CCU以及年龄大于18岁的患者作为CCU患者数据集,对于患者第二次或者多次入院情况数据暂时不予考虑。样本必须能从数据收集窗口中提取出3个模态的医疗数据,包括临床时间序列数据、ECG信号数据和非时序的临床数据。对于筛选过后的数据集中每一个CCU样本,提取进入CCU后的前24 h内的多模态数据,包括MIMIC-III临床数据库中的临床数据和MIMIC-III波形数据库中的ECG第二导联(Lead-II)数据。将患者首次入住CCU作为统计其是否死亡的起点,将患者死亡或者患者在数据库记录时间段内未死亡作为统计的终点。
(2)患者特征纳入:除ECG和ECHO报告外,选用以下几大类特征来构建模型,主要纳入的特征是:①与时间无关的基础变量,包括年龄、性别、民族;
②低频采样变量,包括血氧饱和度、舒张压、收缩压等;
③不规则采样变量,包括血糖、pH值、钠含量(全血)、动脉血氧饱和度等。
总共获得了6 688个事件序列作为实验的数据集,其中80%用于训练,20%用于测试。利用10折交叉验证法进行模型训练与评估,得到10个验证集的结果,并将其平均化为模型的平均结果。同时,根据这些结果进行模型选择和参数调整。
4.2.2 参数选择
在本研究中,采用网格搜索和随机搜索来优化参数,通过结合5折交叉验证来减少结果的偶然性,避免陷入局部最优。为了获得参数的最优组合,实验时,网格搜索不采用缩短步长的方式,而采样穷举策略来寻找参数,实验次数为1轮。随机搜索由于结果的不确定性,实验次数为10轮。
4.2.3 实验方法
本研究融合具有不同结构和时间维度的数据用于死亡预测。分别针对基准的机器学习方法SVM和主流机器学习方法进行预测及评估。实验首先对比基准的机器学习方法SVM,设计了8种预测方法进行预测及评估。
(1)基准方法-无非结构化数据和时间信息的SVM:不会将数据分成与2个时间相关的特征集;
同时不使用文本和波形数据进行预测。
(2)基准方法-无非结构化数据的SVM:将使用时间信息(与时间相关的特征集)进行预测。
(3)基准方法-无时间信息的SVM:使用TF-IDF[22]和统计信息(如平均值、最大值、最小值)用作超声报告和波形数据的特征值。
(4)基准方法-SVM:使用非结构化数据和时间信息的SVM。
(5)本研究方法-无非结构化数据和时间信息:预测无非结构化数据和时间信息。
(6)本研究方法-无非结构化数据:预测没有文本和波形数据。
(7)本研究方法-无时间信息分析:预测没有时间信息。
(8)本研究方法-有非结构化数据和时间信息:预测使用文本和波形数据及时间信息。
其次,实验对比主流机器学习方法,所有方法均在融合非结构化数据和时间信息情况下进行预测及评估。
4.2.4 评估指标
本研究选用的评估指标包括:准确率(Accuracy)、灵敏度(Sensitivity)、特异度(Specificity)、F1值、AUCROC及其AUC-PR值。
4.3 结果分析
定量评估结果如表2所示。

表2 预测性能评估Tab.2 Evaluation of the prediction performance
从表2中可以看到,本研究的方法在AUC-ROC和AUC-PR方面都比基准方法有显著改进。分别从纵向和横向2个方面进行详细分析。
4.3.1 纵向比较
通过分析基准SVM的方法和本研究的方法,推断出二者在预测性能上的差异。对于基准SVM的方法,非结构化数据(无时间信息的SVM)和时间信息(无非结构化数据的SVM)的引入分别比无非结构化数据和时间信息的SVM在AUC-ROC/AUC-PR上分别获得1.36%/3.94%和2.4%/3.41%的改进。而组合使用非结构化数据和时间信息的SVM获得3.64%/9.38%提升,对于本研究的的方法,可以得出类似的结论,如图3所示。由此可见,通过引入多模态数据,可以获得更好的动态死亡风险预测性能。
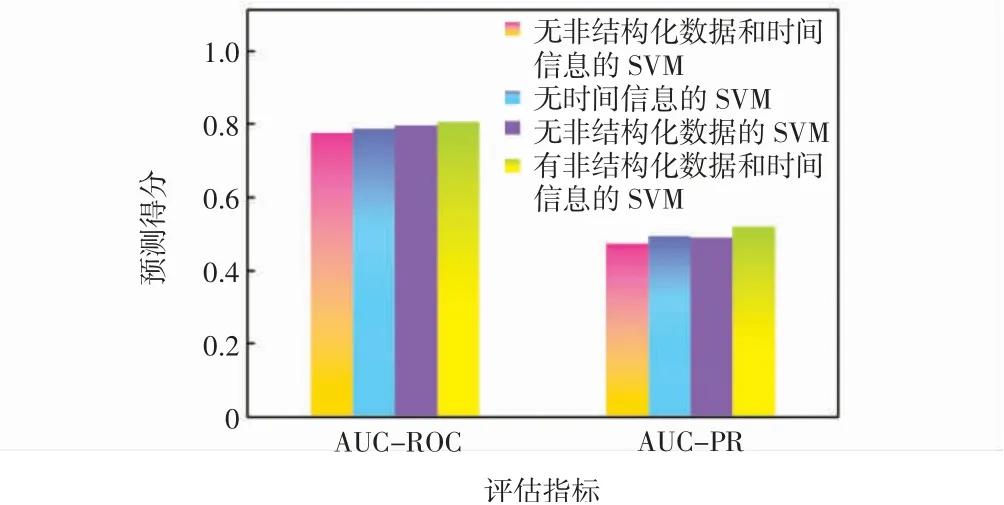
图3 基于SVM方法的预测得分Fig.3 Prediction score based on SVMmethod
4.3.2 横向比较
给定相同的数据类型,重点讨论基准的SVM方法和本研究之间的差异。
首先,通过对不含时间信息的方法的比较,发现引入非结构化数据,本研究在AUC-ROC上比基准的SVM(0.776 9~0.787 5)有更大的改进(0.841 0~0.872 1),在AUC-ROC/AUC-PR上的改进分别为8.25%/14.26%和10.74%/21.06%。原因是本研究在方法中使用了更先进的技术从非结构化数据中提取特征,即:CNN用于文本数据处理;
信号处理方法用于波形数据。
通过对含时间信息的方法的比较,分析无非结构化数据和有非结构化数据及时间信息的方法,结果标明本研究的性能较基准的SVM在AUC-ROC/AUCPR上获得9.31%/18.25%和11.36%/25.31%的改进。原因之一可能是基准的SVM中变量独立性的假设在很大程度上限制了多模态融合的能力,而XGBoost等机器学习方法可以更好地处理海量数据。
4.3.3 与其他主流机器学习模型对比分析
除了从纵向和横向2个方面进行对比,为了更好的验证本研究模型的性能,将本研究模型与4种主流机器学习算法进行对比,使用准确率、灵敏度、特异度、F1值、AUC值5个指标进行模型评估,如表3所示。将处理后数据集的80%划分为训练集,20%划分为测试集,各模型均使用默认参数。

表3 主流机器学习模型的指标比较结果Tab.3 Comparison of index for mainstream machine learning models
由表3中对比的实验结果可知:
(1)在融合非结构化数据和时间信息的情况下,对比基于线性分类的逻辑回归模型,本研究在AUC上获得11.42%的改进。这表明CCU临床数据通常表现出复杂的非线性关系,所以基于非线性关系的模型可以获得较好的分类效果。
(2)基于集成算法的模型在数据集上均表现较好,本研究采用的XGBoost算法是集成学习boosting方法的一种,实验表明,在融合非结构化数据和时间信息的情况下,本研究较随机森林、GradientBoost、AdaBoost在AUC上获得平均1.31%的改进。原因是XGBoost在目标函数中加上了正则化项,使学习出来的模型更加简单,有效地防止过拟合。
(3)XGBoost模型在训练之前,对输入特征数据排序,存储为Block结构,在之后的预测过程中重复地使用这个结构,很大程度上减少了计算量,可以在预测中实现并行计算,因此具有更快的预测速度。综合比较上述指标,在5种算法中,XGBoost算法预测结果相比其他算法更加优秀。
在本研究中,由于采用数据多模态融合策略,建模的所有特征都是结构化的。XGBoost提供了一个关于特征的权重,该权重体现了每个特征在构建预测模型中的价值。通过统计权重最高的前20个特征的特征类型,得到1个与时间无关特征(年龄)、3个与心电图相关特征、9个低频采样特征(血压/心率/呼吸频率相关)和7个不规则采样特征(pH/血糖/体温相关)。这些特征中的大部分来源于最近和较近的特征集。以上结果表明,CCU数据的多模态性对提高预测模型的准确率起着重要的作用。
本文从结构和时间2个维度对CCU数据进行了分类。为了融合文本形式和波形等非结构化数据,应用深度学习和信号处理技术提取其结构化特征。为了融合不同时间粒度的数据,采用不同的策略构造具有时间属性的特征集。通过对MIMIC-III数据集中CCU数据的预测,结果表明:
(1)采用有效的融合策略,非结构化数据(无时间信息的SVM)和时间信息(无非结构化数据的SVM)的引入分别比无非结构化数据和时间信息的SVM在AUC-ROC/AUC-PR上获得1.36%/3.94%和2.4%/3.41%的改进。组合使用非结构化数据和时间信息的SVM在AUC-ROC/AUC-PR上获得3.64%/9.38%提升。
(2)使用CNN、信号处理等先进的技术从非结构化数据中提取特征的方法,通过基准的SVM方法和本研究方法的分析,对不含时间信息的方法的比较,引入非结构化数据,本研究在AUC-ROC/AUC-PR上的改进分别为8.25%/14.26%和10.74%/21.06%。对含时间信息的方法的比较,引入非结构化数据,本研究在AUC-ROC/AUC-PR上获得9.31%/18.3%和11.36%/25.31%的改进。
(3)与主流机器学习模型对比分析,对于基于线性分类的模型,本研究在AUC上获得11.42%的改进。对于其他基于集成算法的模型,在AUC上平均获得1.31%的改进,本算法减少了计算量具有更快的预测速度。
猜你喜欢结构化模态预测基于BERT-VGG16的多模态情感分析模型成都信息工程大学学报(2022年4期)2022-11-18无可预测黄河之声(2022年10期)2022-09-27选修2-2期中考试预测卷(A卷)中学生数理化(高中版.高二数学)(2022年4期)2022-05-25选修2-2期中考试预测卷(B卷)中学生数理化(高中版.高二数学)(2022年4期)2022-05-25多模态超声监测DBD移植肾的临床应用昆明医科大学学报(2022年3期)2022-04-19跨模态通信理论及关键技术初探中国传媒大学学报(自然科学版)(2021年1期)2021-06-09促进知识结构化的主题式复习初探河北理科教学研究(2021年4期)2021-04-19改进的非结构化对等网络动态搜索算法军民两用技术与产品(2021年2期)2021-04-13结构化面试方法在研究生复试中的应用计算机教育(2020年5期)2020-07-24左顾右盼 瞻前顾后 融会贯通——基于数学结构化的深度学习福建基础教育研究(2020年3期)2020-05-28